










deepseek 模型的“顿悟时刻”再研究:自我反思并非训练的关键
近期围绕DeepSeek模型的“顿悟时刻”(模型展现出自我反思等涌现能力)引发广泛关注。然而,新加坡Sea AI Lab等机构的研究者对这一现象进行了深入探究,并得出了一些与先前认知不同的结论。
过去的研究认为,DeepSeek-R1-Zero通过强化学习(RL)实现了“顿悟”,模型学会了自我反思,从而提升了复杂推理能力。此后,多个项目在较小规模模型上复现了类似的训练过程,并观察到响应长度增加的现象,这被认为是“顿悟”的标志。
然而,最新研究表明,这种“顿悟时刻”可能并非RL训练的结果,而是在基础模型中就已存在。研究者在多种基础模型(如Qwen-2.5、DeepSeek-Math等)中,仅通过简单的提示工程,就观察到了类似的自我反思行为,包括使用关键词如“让我检查一下”、“等等”等。 这表明,基础模型本身就具备一定的自我反思能力,并非RL训练的产物。



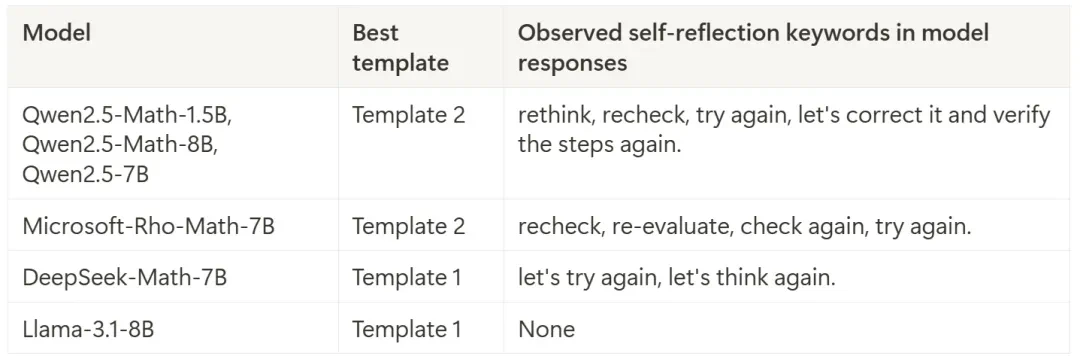
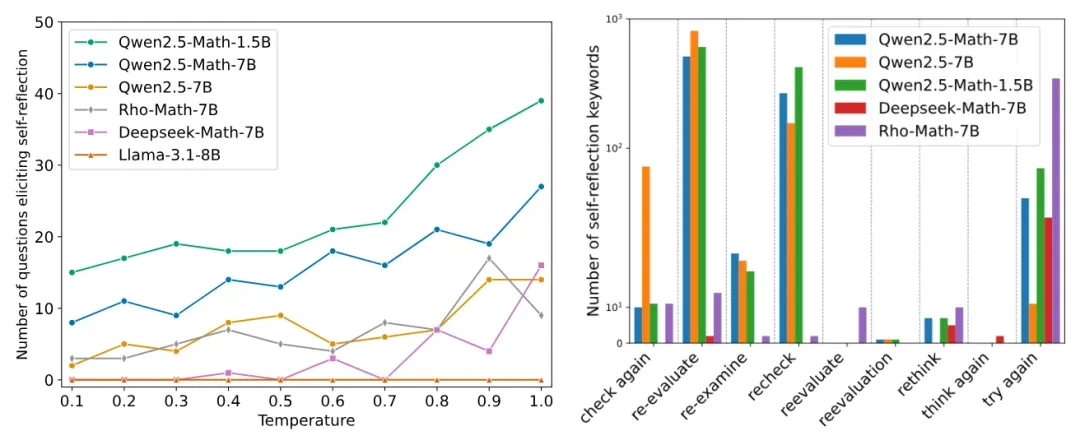
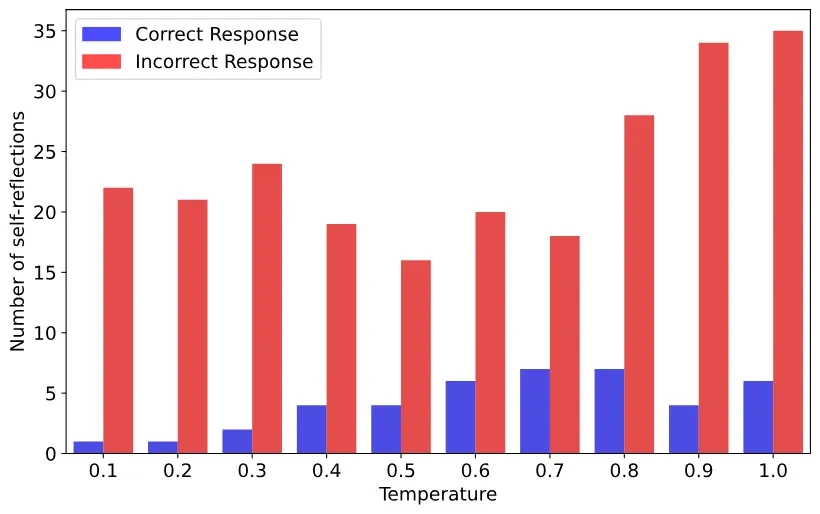
研究者还发现,这种自我反思并非总是有效的,他们将其称为“肤浅的自我反思(SSR)”。SSR可能导致模型在原本正确的答案中引入错误,或者反复反思却无法得出有效答案。 实验表明,基础模型更容易产生SSR,并非所有自我反思都能带来更准确的结果。





此外,研究者发现响应长度的增加并非自我反思的直接结果,而是RL训练中奖励函数优化的结果。通过在倒计时任务和数学问题上进行RL训练,他们观察到响应长度先减少后增加的现象,这与奖励函数的优化过程密切相关。 这表明,响应长度并非衡量模型自我反思能力的可靠指标。
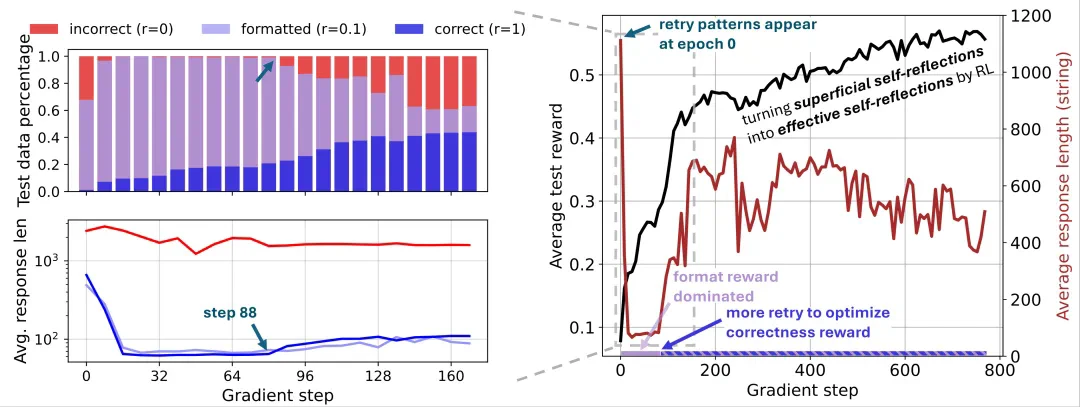

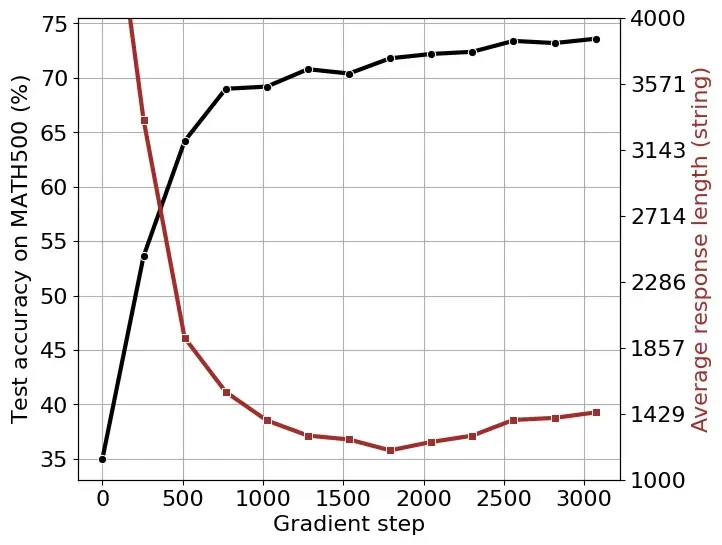
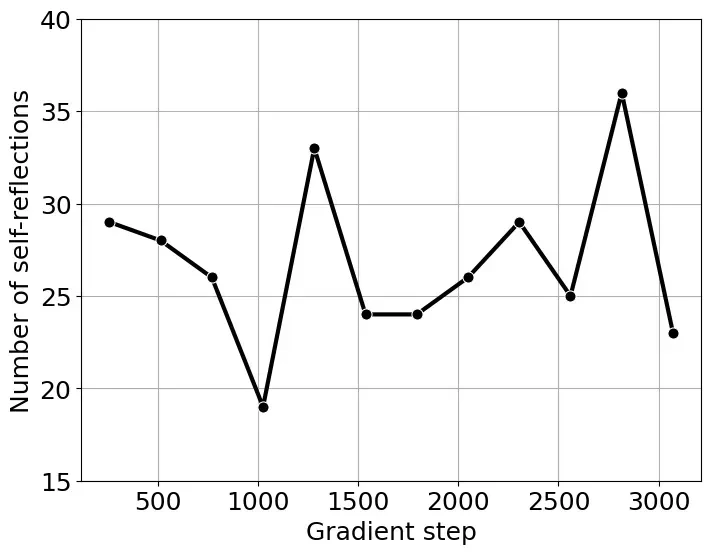
总而言之,这项研究对DeepSeek模型的“顿悟时刻”提出了新的解读,认为先前观察到的现象可能被夸大了,自我反思并非RL训练的关键,而响应长度的增加主要由奖励函数优化驱动。 这为未来大型语言模型的研究提供了新的方向和思考。