










字节跳动开源全新代码大模型评估基准fullstack bench,全面升级编程能力评测标准!该基准涵盖11大类真实应用场景、16种编程语言和3374个问题,远超现有基准,更精准地评估大模型的实际代码开发能力。
现有代码评估基准如HumanEval、MBPP、DS-1000和xCodeEval等,在应用场景和编程语言覆盖方面存在局限性,难以全面反映真实开发环境的复杂性。 FullStack Bench则突破了这一瓶颈。

FullStack Bench数据覆盖范围显著领先现有基准
FullStack Bench 基准数据集由字节跳动大模型团队与M-A-P开源社区合作打造。研究团队分析了Stack Overflow上的50万个问题,从中筛选出涵盖真实全栈开发的11个主要应用领域,并对每个领域的样本进行了调整,确保基准的稳健性。
FullStack Bench数据集构成
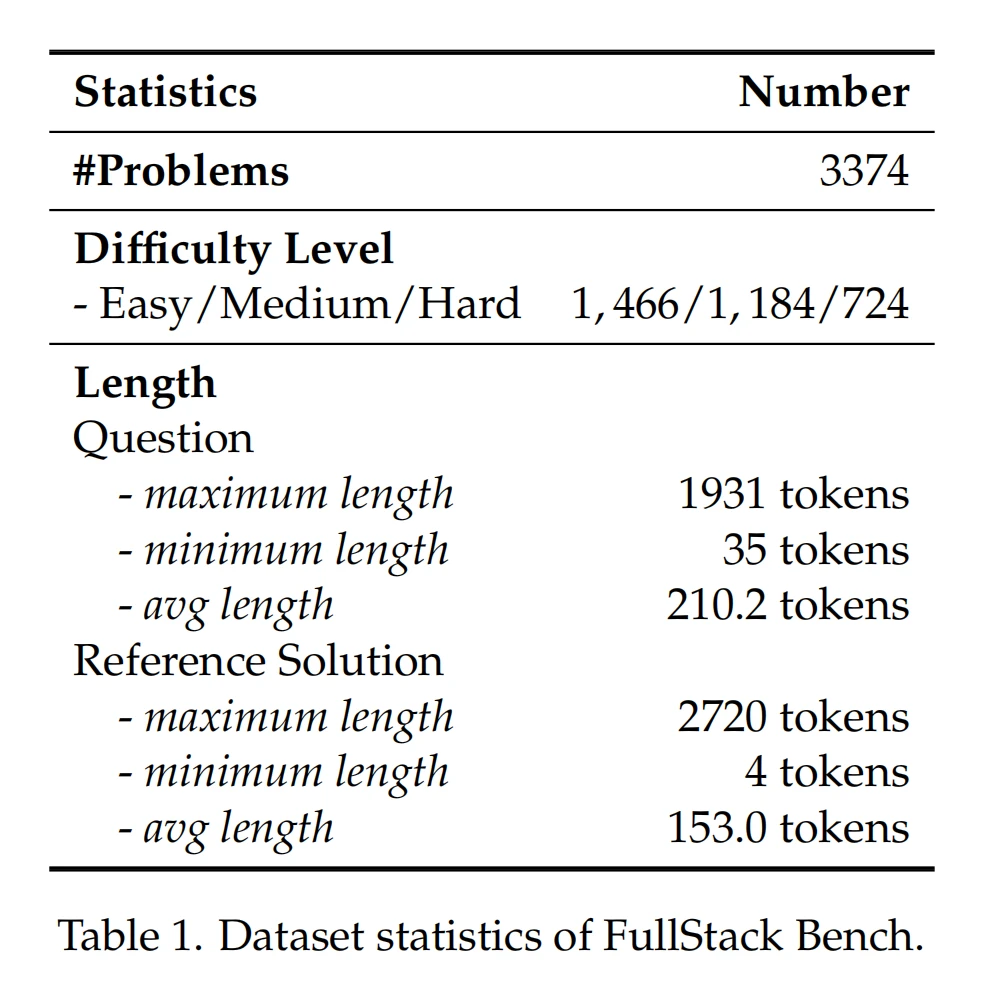
该基准包含3374个问题,每个问题都配有详细描述、参考解决方案和单元测试用例(共15168个)。所有问题均由专家设计,并经过严格的AI和人工审核,确保数据质量。
为方便开发者测试,团队还同步开源了高效的代码沙盒执行工具SandboxFusion,支持FullStack Bench及其他10多个数据集,兼容23种编程语言。开发者可轻松部署和使用SandboxFusion,进行大模型代码能力的系统性评估。

此外,字节跳动还首次公开其自研代码大模型Doubao-Coder的评测结果,并将其与其他20余款代码大模型进行了对比分析(详见论文)。 值得一提的是,字节跳动自研的AI编程助手豆包MarsCode,每月已为用户提供百万量级代码支持。
- 论文地址:
- 数据集开源地址:
- 沙盒开源地址:
- 沙盒体验入口: