AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com




论文标题:Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study 论文地址:https://arxiv.org/pdf/2404.10719
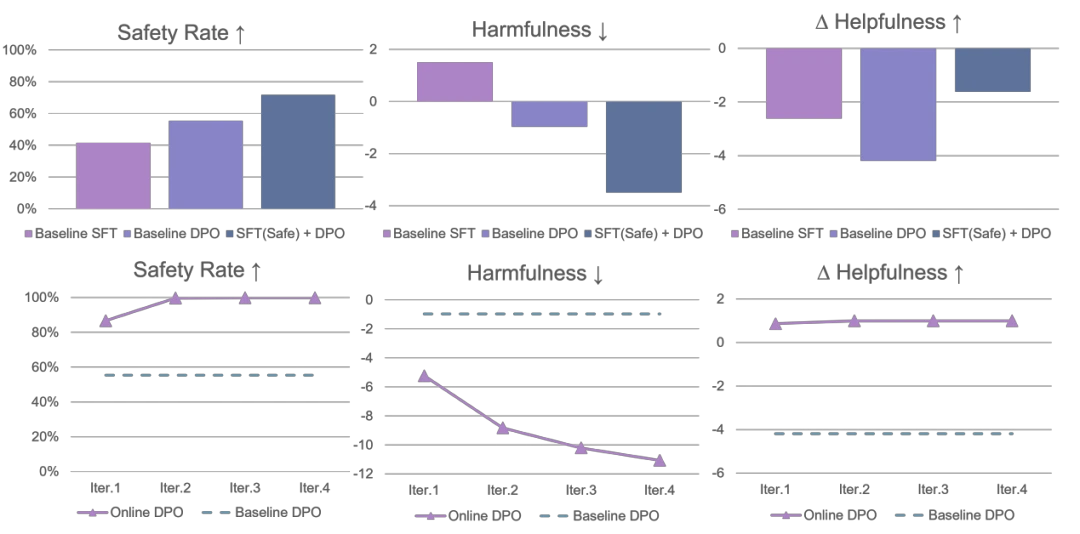
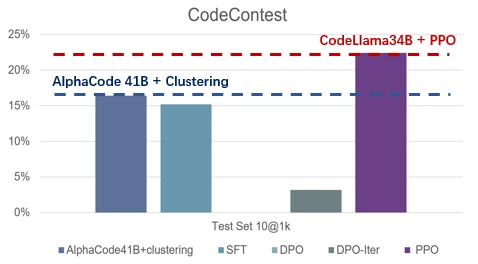
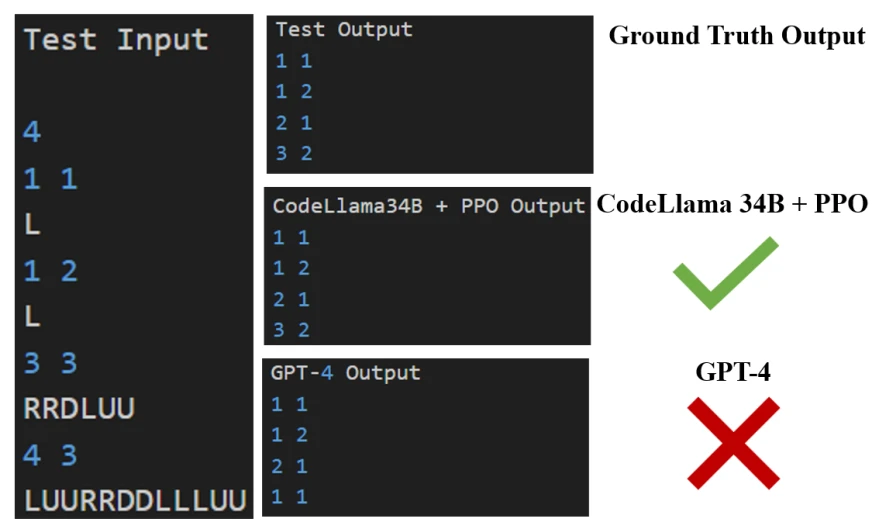
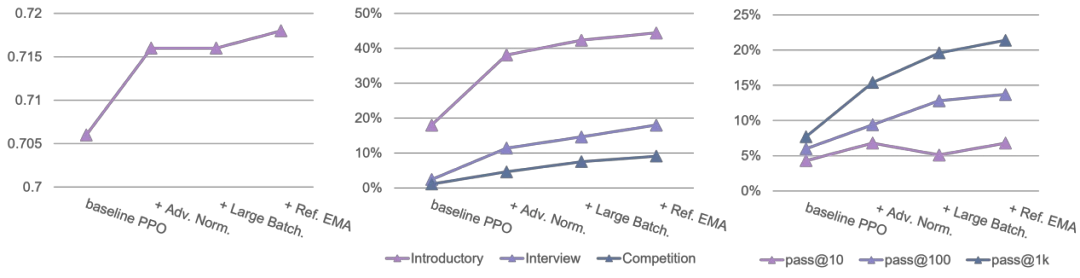
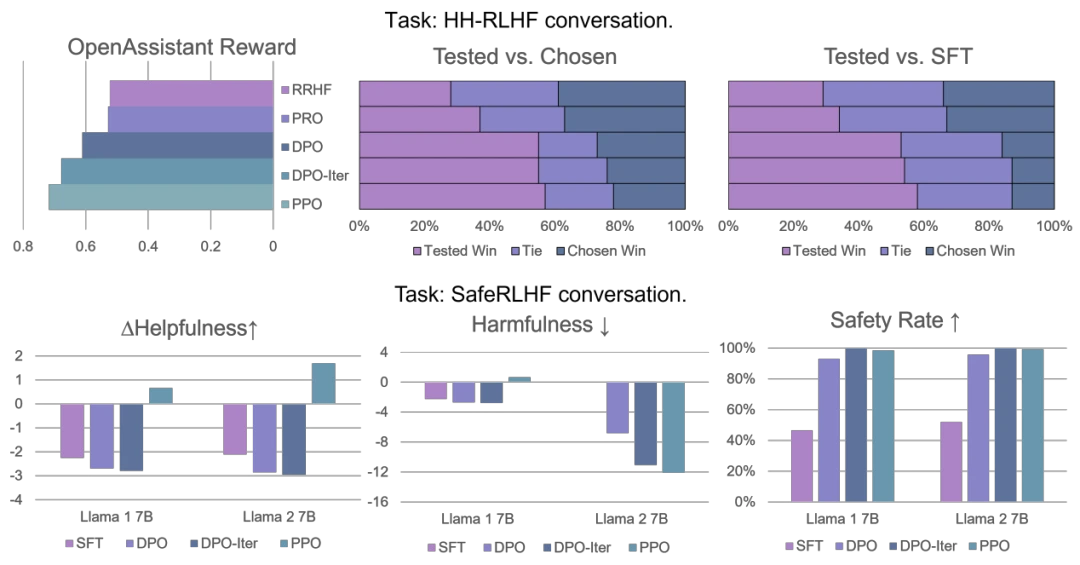
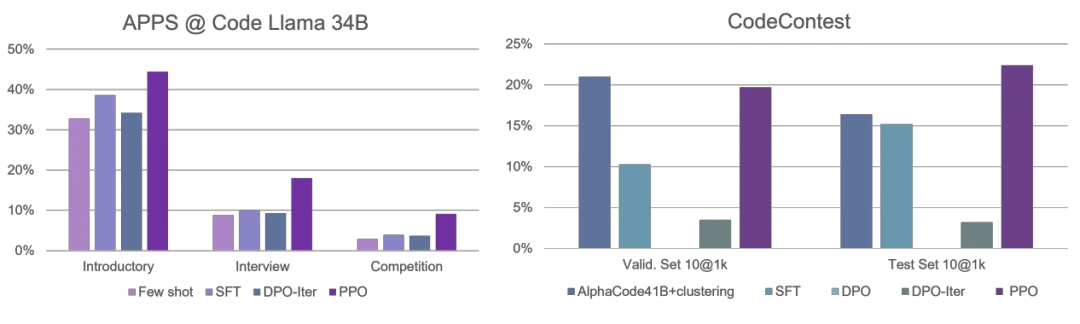
使用大的批大小(large batch size) 优势归一化(advantage normalization) 以及对 reference model 使用指数移动平均进行更新(exponential moving average for the reference model)。
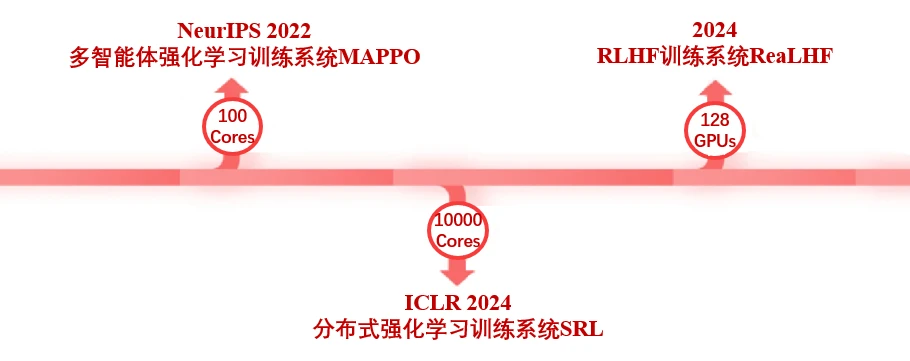
NeurIPS 2022 The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games [1]:提出并开源了用于多智能体的强化学习并行训练框架 MAPPO,支持合作场景下的多智能体训练,该工作被大量多智能体领域工作采用,目前论文引用量已超过 1k。 ICLR 2024 Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores [2]: 提出了用于强化学习的分布式训练框架,可轻松扩展至上万个核心,加速比超越 OpenAI 的大规模强化学习系统 Rapid。 ReaLHF: Optimized RLHF Training for Large Language Models through Parameter Reallocation [3]: 最近,吴翼团队进一步实现了分布式 RLHF 训练框架 ReaLHF。吴翼团队的 ICML Oral 论文正是基于 ReaLHF 系统产出的。ReaLHF 系统经过长时间的开发,经历大量的细节打磨,达到最优性能。相比于之前的开源工作,ReaLHF 可以在 RLHF 这个比预训练更复杂的场景下达到近乎线性的拓展性,同时具有更高的资源利用率,在 128 块 A100 GPU 上也能稳定快速地进行 RLHF 训练,相关工作已开源:https://github.com/openpsi-project/ReaLHF