提供丰富的素材资源、软件工具、源码模板、技术文章和编程教程,专注于网站搭建、AI应用、开源项目分享和工具推荐。帮助开发者轻松获取所需资源,快速提升技术水平。
首页
素材
平面素材
音频素材
视频素材
AE素材
3D素材
模板
Code代码
Wordpress模板
Cms模板
html模板
文章
数据库
薅羊毛
资源
应用插件
工具下载
建站源码
搜索新闻相关内容
search
热词:
YouTuBe
Disney
Netflix
iCloud+
HBOMax
GPTPro
Spotify
合租&账号
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
2024-10-03 01:53
16
标签导航:
效果更稳定,实现更简单。
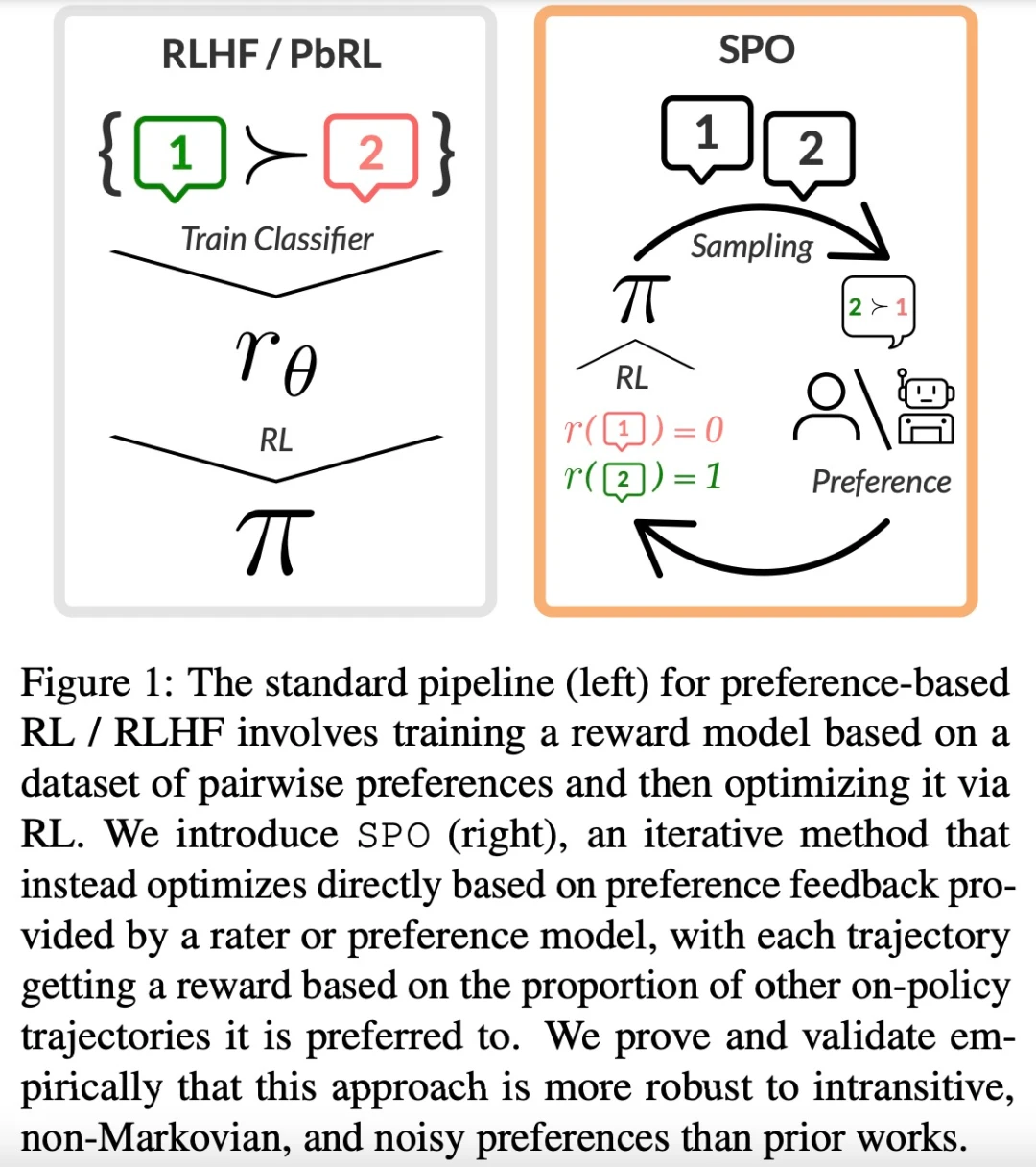
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一些不良影响。
来自卡内基梅隆大学(CMU)和 Google Research 的研究者联合提出了一种简单的、理论上严格的、实验上有效的 RLHF 新方法 —— 自我博弈偏好优化(Self-Play Preference Optimization,SPO)。该方法消除了奖励模型,并且不需要对抗性训练。
论文:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
论文地址:https://arxiv.org/abs/2401.04056
方法简介
SPO 方法主要包括两个方面。首先,该研究通过将 RLHF 构建为两者零和博弈(zero-sum game),真正消除了奖励模型,从而更有能力处理实践中经常出现的噪声、非马尔可夫偏好。其次,通过利用博弈的对称性,该研究证明可以简单地以自我博弈的方式训练单个智能体,从而消除了不稳定对抗训练的需要。
实际上,这相当于从智能体中采样多个轨迹,要求评估者或偏好模型比较每对轨迹,并将奖励设置为轨迹的获胜率。
SPO 避免了奖励建模、复合 error 和对抗性训练。通过从社会选择理论(social choice theory)中建立最小最大获胜者的概念,该研究将 RLHF 构建为两者零和博弈,并利用该博弈支付矩阵的对称性来证明可以简单地训练单个智能体来对抗其自身。
该研究还分析了 SPO 的收敛特性,并证明在潜在奖励函数确实存在的情况下,SPO 能以与标准方法相媲美的快速速度收敛到最优策略。
实验
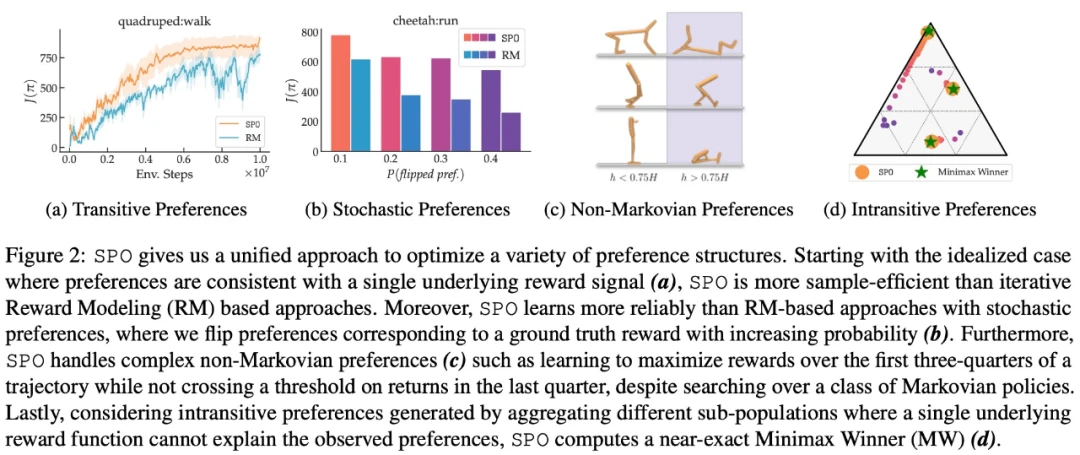
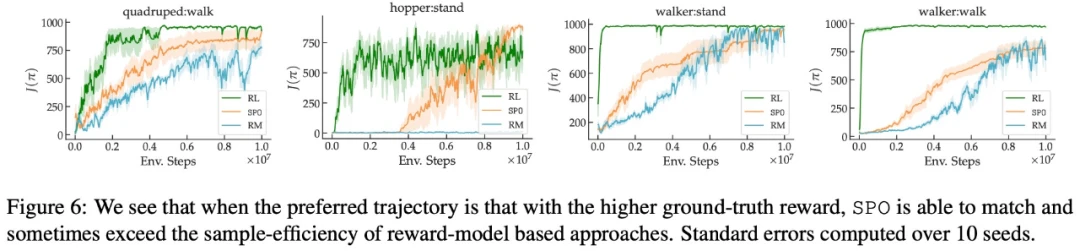
该研究在一系列具有现实偏好函数的连续控制任务上,证明了 SPO 比基于奖励模型的方法性能更好。SPO 在各种偏好设置中能够比基于奖励模型的方法更有效地学习样本,如下图 2 所示。
该研究从多个维度将 SPO 与迭代奖励建模 (RM) 方法进行比较,旨在回答 4 个问题:
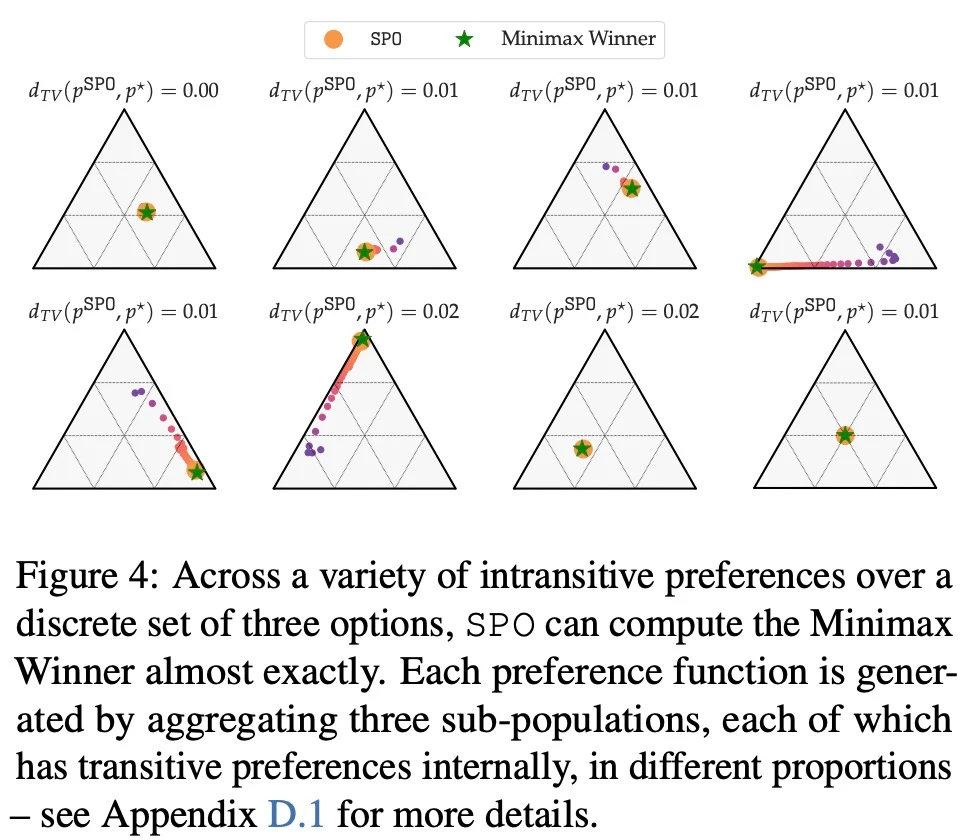
当面 intransitive 偏好时,SPO 能否计算 MW?
在具有独特 Copeland Winners / 最优策略的问题上,SPO 能否匹配或超过 RM 样本效率?
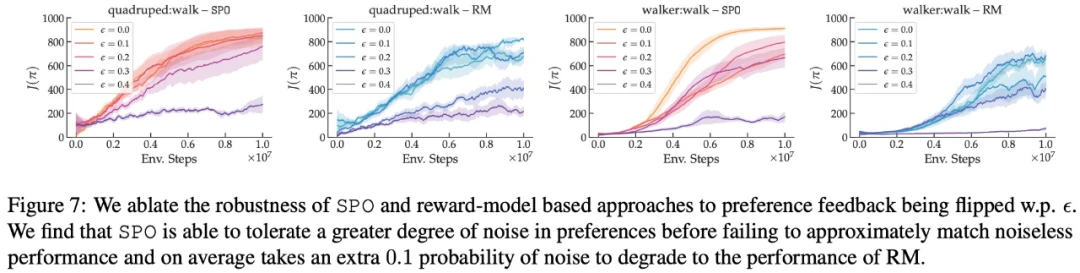
SPO 对随机偏好的稳健性如何?
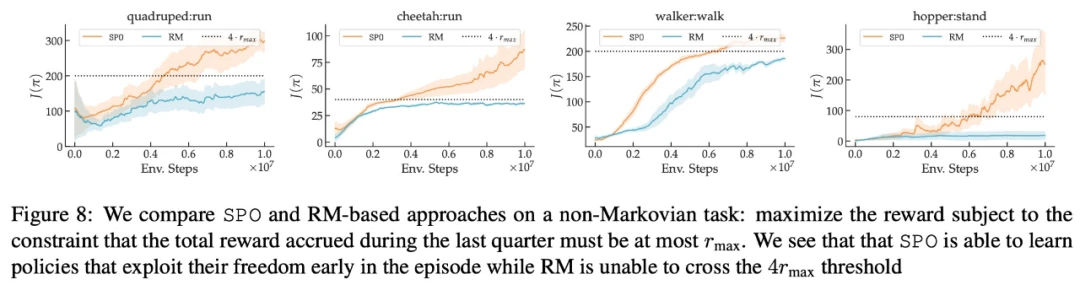
SPO 可以处理非马尔可夫偏好吗?
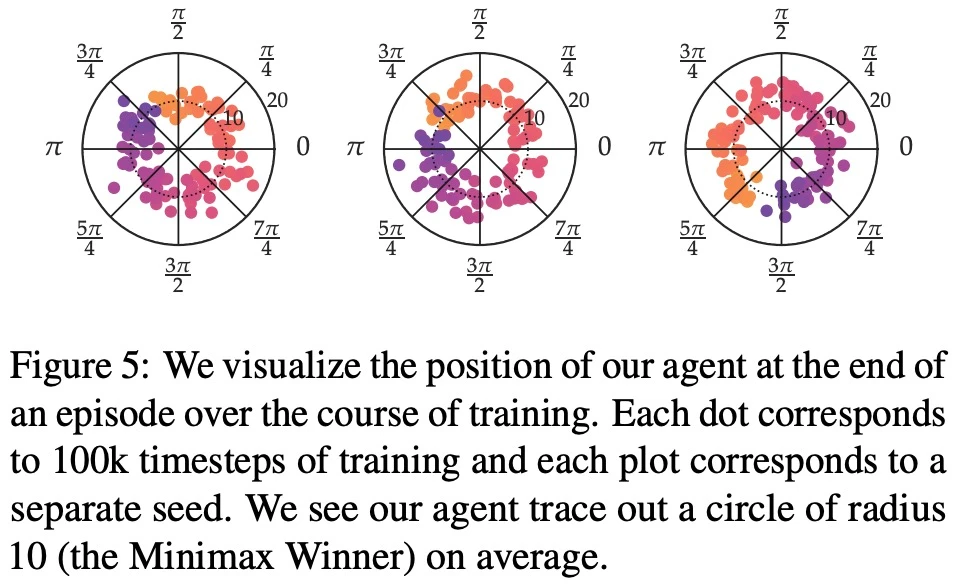
在最大奖励偏好、噪声偏好、非马尔可夫偏好方面,该研究的实验结果分别如下图 6、7、8 所示:
感兴趣的读者可以阅读论文原文,了解更多研究内容。
如何探索和可视化用于图像中物体检测的 ML 数据
三年16篇一作,前谷歌研究科学家Yi Tay官宣新模型,21B媲美Gemini Pro
相关文章推荐
英伟达 不要妨碍我们打怪猎啊!N卡新驱动bug导致掉帧
RTX 50 系列显卡遭诟病,软件故障与驱动困境并存
苹果新版个人化Siri 将延迟至2026年推出时间仍未定
爆料:微软正开发内部AI推理模型!可以与OpenAI o1媲美
疾速掠影,愈战驭强!AGON AG276QSD助你驰骋FPS战场
续航卷起来了!曝苹果折叠屏手机将搭载5000mAh电池
iPhone 17系列新机模上手图!背摄设计太过瞩目
曝字节跳动曾想收购Manus团队 但因出价太低被拒绝!
AMD 9900X3D/9950X3D 3月12日上市!价...
跌麻了!特斯拉股价暴跌15% 市值一夜蒸发1300亿美元
被困太空9个月!美国两名宇航员3月19日将回到地球
防喵星人误触就选华硕机箱,游戏创作安心无忧