










深度解析:大模型的自我改进能力为何参差不齐?斯坦福大学最新研究揭秘
近期,斯坦福大学的一项研究深入探讨了大型语言模型(LLM)自我改进能力背后的机制,解释了为何有些模型能够有效利用额外计算资源提升性能,而另一些则停滞不前。该研究的核心在于模型的初始“认知行为”。
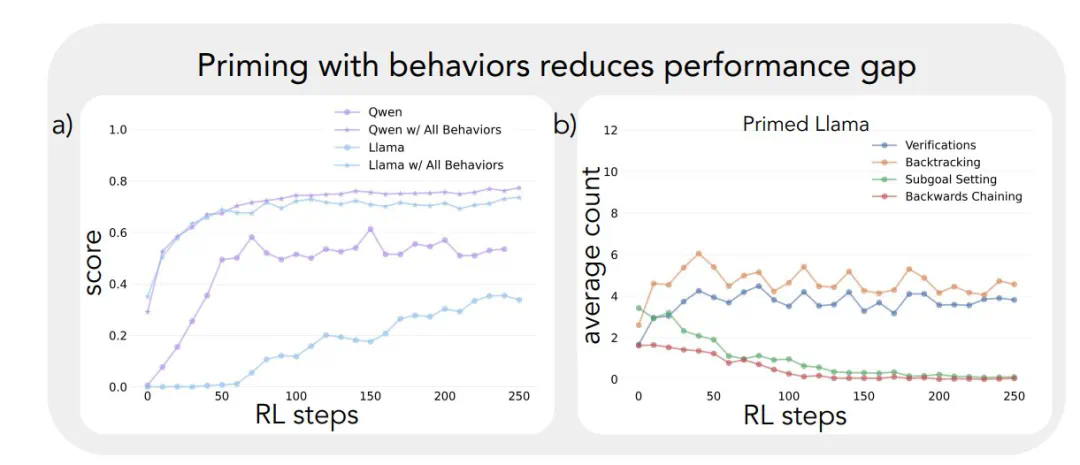
研究人员选取了Qwen-2.5-3B和Llama-3.2-3B两个模型进行对比,利用强化学习训练它们解决Countdown数学游戏。结果显示,Qwen的准确率从初始的低分跃升至约60%,而Llama仅提升至30%。
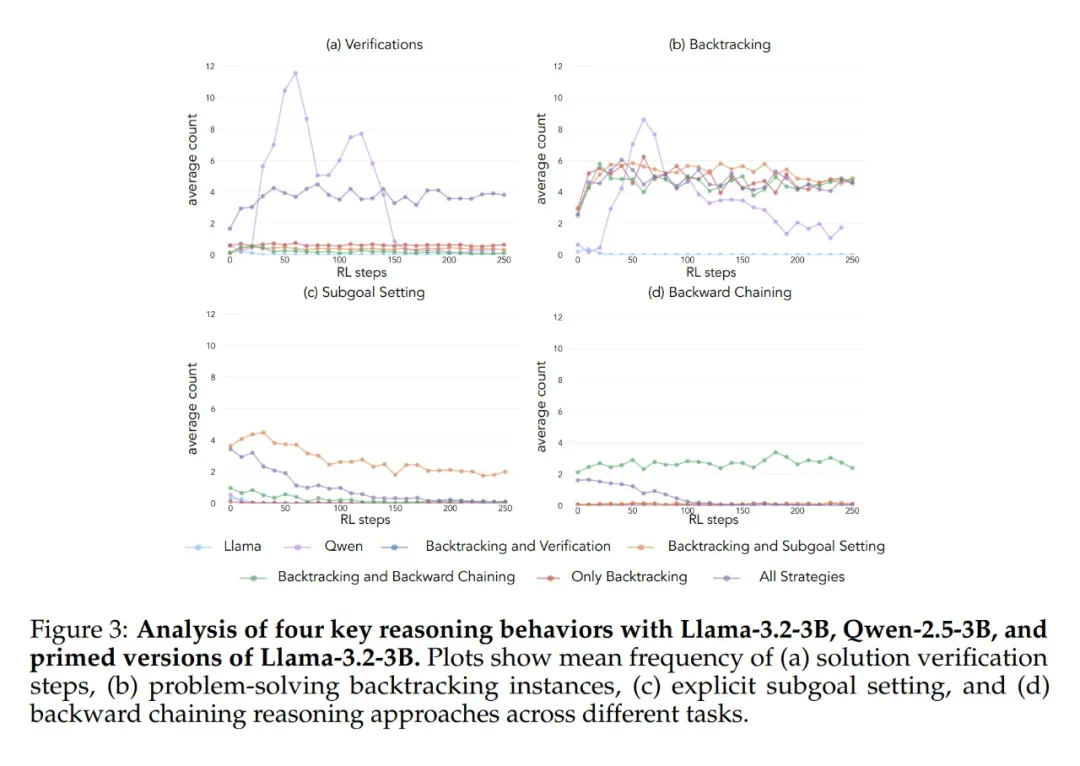
为了解释这种差异,研究者提出了一个分析认知行为的框架,涵盖四个关键行为:验证、回溯、子目标设定和逆向思考。这些行为类似于人类专家解决复杂问题的方式。
研究发现,Qwen模型天然地展现出这些行为,特别是验证和回溯,而Llama则缺乏这些能力。这表明,模型初始的推理行为对其自我改进能力至关重要。即使给予更多计算资源和时间,缺乏这些基本思考能力的模型也无法有效利用这些资源。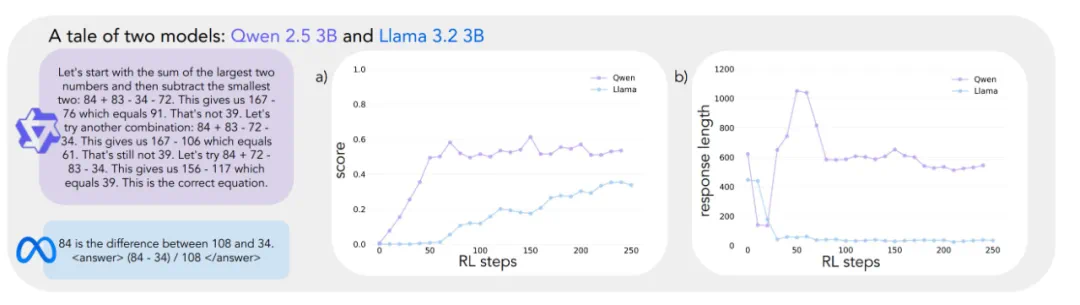
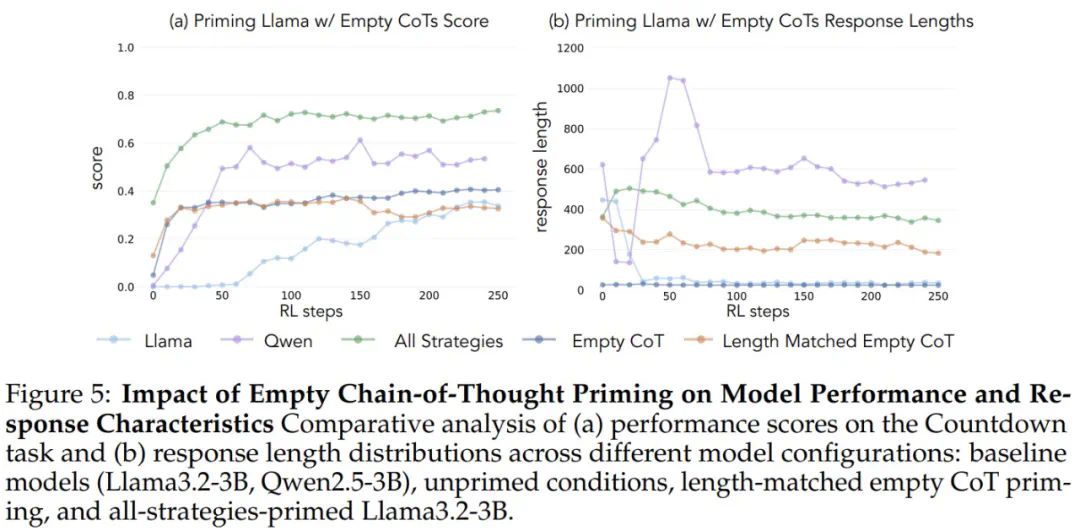
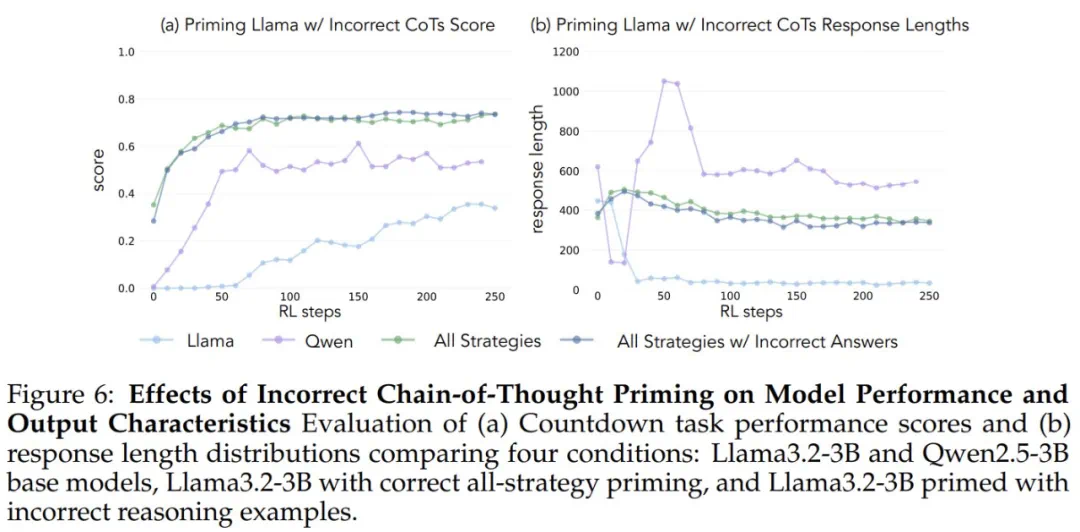
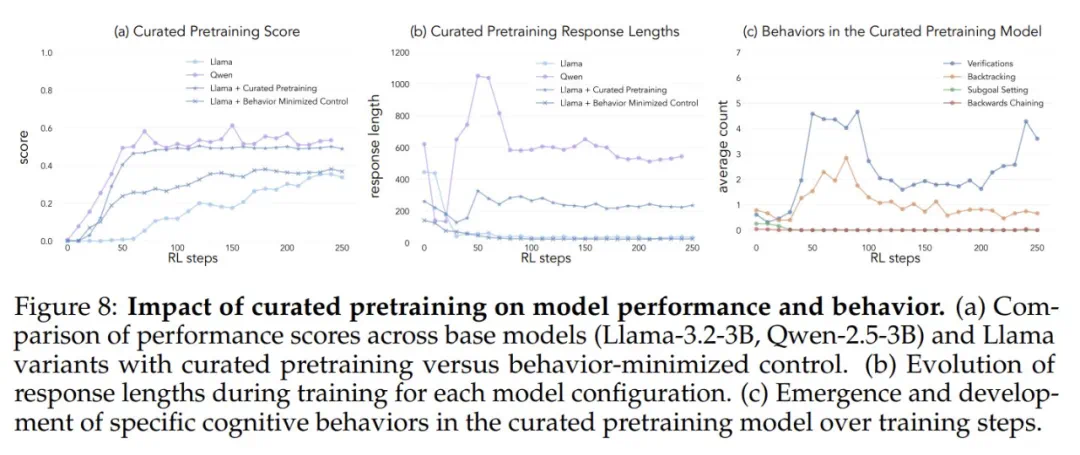
为了验证这一假设,研究人员进行了干预实验。他们使用人工合成的推理轨迹对Llama进行引导,这些轨迹包含了上述认知行为,特别是回溯。结果显示,Llama的性能得到了显著提升,甚至接近Qwen的水平。即使这些引导轨迹包含错误答案,只要展现出正确的推理模式,Llama仍然能够进步。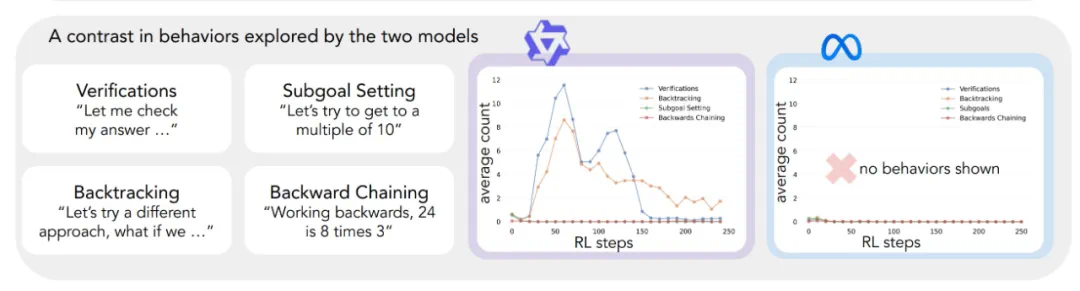 这表明,推理行为本身,而非正确答案,才是关键。
这表明,推理行为本身,而非正确答案,才是关键。
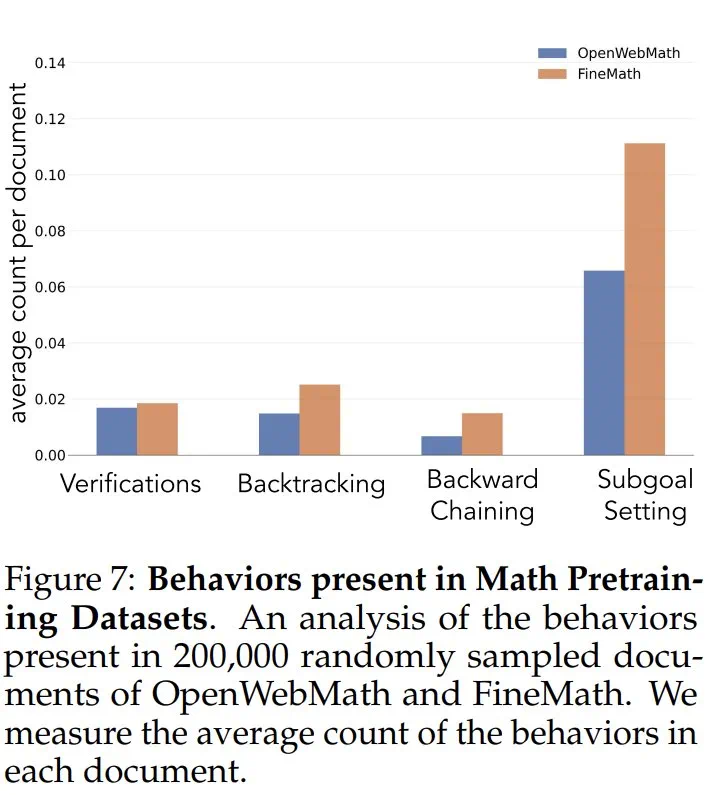
此外,研究人员还通过调整Llama的预训练数据,使其包含更多强调这些认知行为的内容。结果同样表明,这种方法能够成功诱导出高效利用计算资源所需的推理行为模式,Llama的性能提升轨迹与Qwen趋于一致。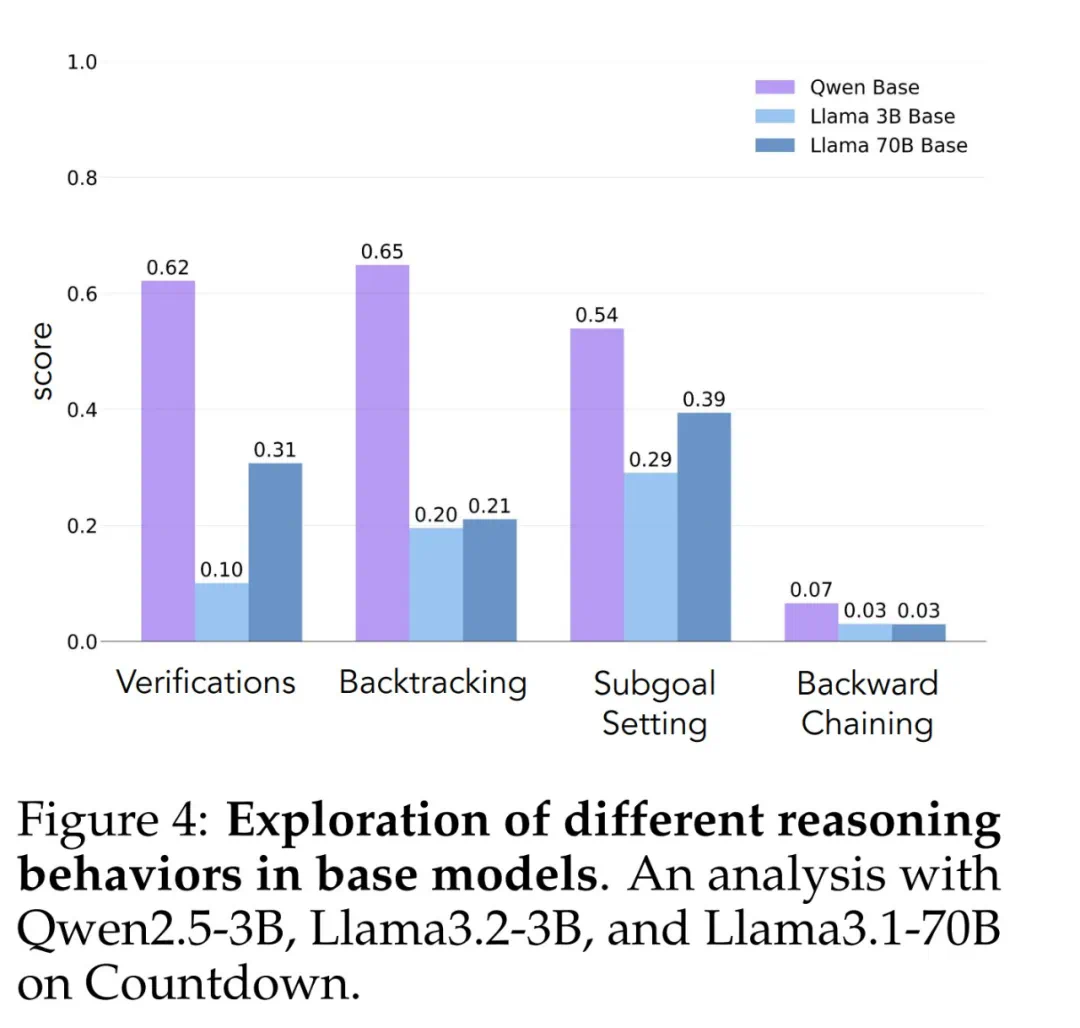
这项研究的结论是:模型的初始推理行为与其自我改进能力密切相关。理解这些动态变化对于开发能够显著提升问题解决能力的AI系统至关重要。 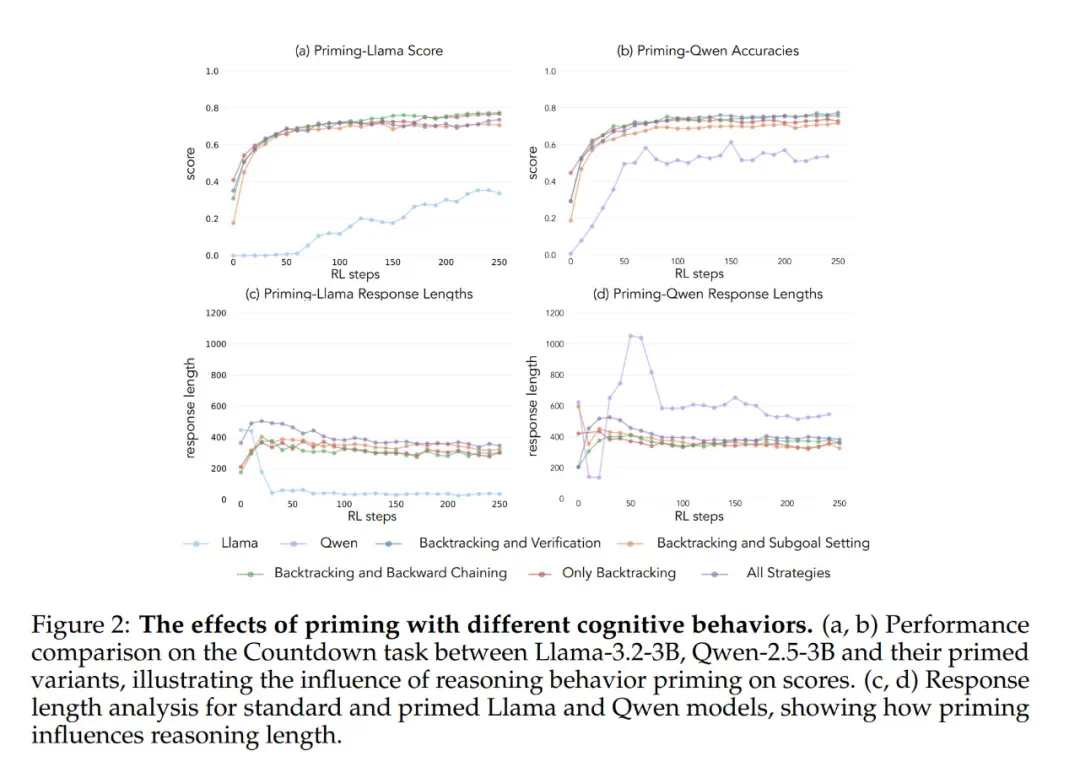
 研究链接:https://www.php.cn/link/9e1c2f13d481c7ccc6673a3ac668799f
研究链接:https://www.php.cn/link/9e1c2f13d481c7ccc6673a3ac668799f