










摩尔线程科研团队在 arxiv 上发表最新研究成果《round attention:以轮次块稀疏性开辟多轮对话优化新范式》,该方法显著提升了大型语言模型(llm)的多轮对话推理效率。 round attention 的端到端延迟低于现有主流的 flash attention 推理引擎,并大幅降低了 kv 缓存的 gpu 显存占用(节省 55% 到 82%)。
近年来,LLM 的广泛应用凸显了多轮对话场景下两大瓶颈:计算开销巨大和 GPU 内存需求高涨。摩尔线程的 Round Attention 正是针对这两个问题提出的解决方案。
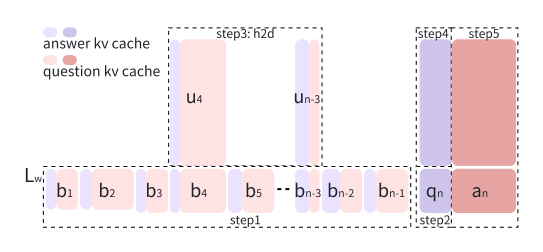
Round Attention 的核心创新:
Round Attention 以轮次为单位优化 Attention 机制,并基于对多轮对话 Attention 分布规律的深入研究,提出了独特的推理流程。其主要优势体现在:
- 语义完整性: 将 KV 缓存按轮次划分,确保每次 Attention 计算都基于完整的语义单元,提升模型理解能力。
- 注意力稳定性: 发现并利用了特定“分水岭层”后注意力分布的高度相似性,仅需在此层筛选关键轮次,减少后续计算开销。
- 存储与传输优化: 将 KV 缓存分块存储于 CPU 内存,并以轮次为单位批量传输,降低了 GPU 内存占用和数据传输延迟。
性能提升:
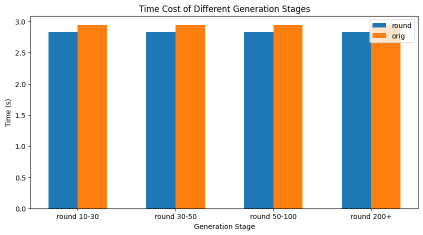
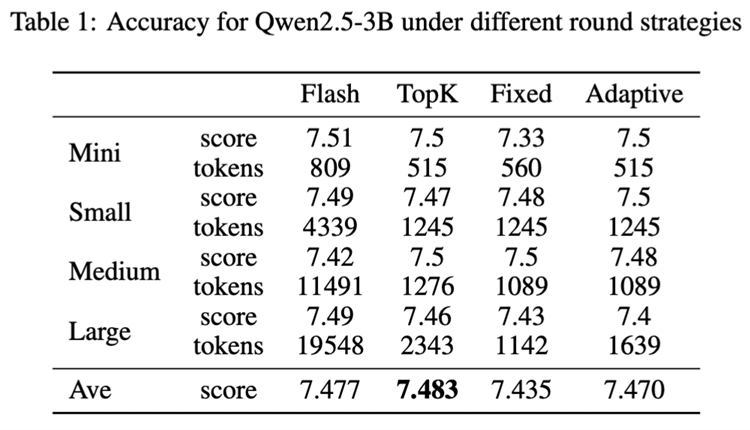
Round Attention 在保持模型推理精度的前提下,实现了显著的性能提升:端到端延迟低于 Flash Attention,KV 缓存显存占用降低 55% 到 82%。
未来展望:
摩尔线程团队希望与开源社区合作,进一步探索稀疏注意力优化,共同解决 LLM 落地应用中的效率和成本难题。 论文全文已可在 arXiv 上获取:
https://www.php.cn/link/65b22292b232047ac742de249504db02