










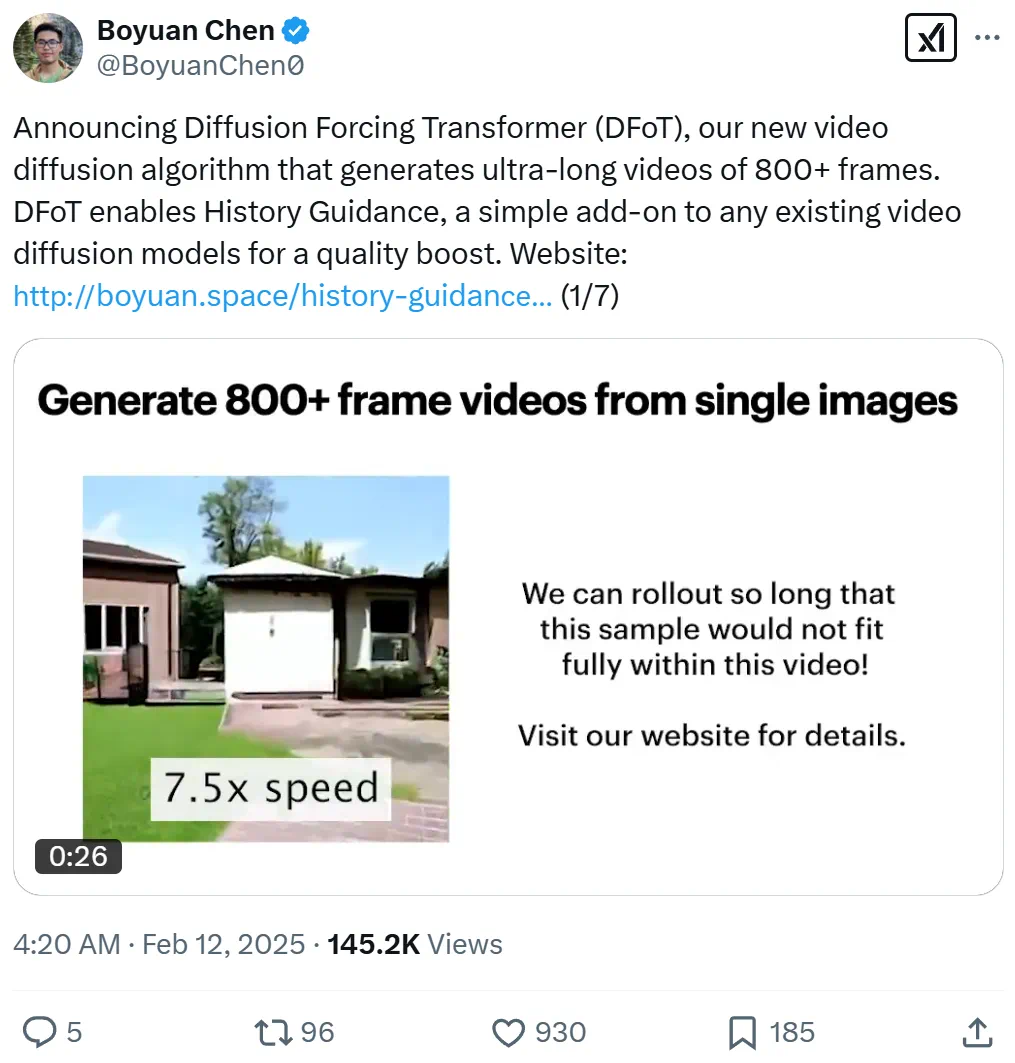
年,视频生成技术,特别是基于扩散模型的视频生成,持续发展创新,涌现出众多令人惊艳的文生视频和图生视频模型。然而,长视频生成一直是该领域的一大难题。麻省理工学院(mit)团队近期发表的论文《history-guided video diffusion》提出了一种名为diffusion forcing transformer (dfot) 的全新算法,无需改有模型架构,即可实现视频生成长度提升近50倍,达到近千帧。

论文地址: 项目主页:
生成的视频长度惊人,需截短并降低帧率才能展示。先睹为快:
现有视频扩散模型广泛采用无分类器引导(CFG)来提升采样质量,但通常仅利用首帧信息,忽略了后续帧的重要性。MIT团队的研究表明:历史信息是提升视频生成质量的关键!

该论文通过混合长短历史模型的预测结果,提出了一系列“历史引导”算法,显著提升了视频扩散模型的质量、生成长度、鲁棒性和可组合性。

在X平台上,论文共同一作陈博远分享的研究成果获得了极高的关注度。
研究科学家George Kopanas高度评价了这项工作,认为其成果令人印象深刻。

核心方法:
论文首先训练了一个能够根据不同历史信息进行去噪预测的视频模型,包括不同长度的历史、历史的不同子集以及特定频率域的历史。 然而,现有模型架构缺乏这种灵活性。 DFoT算法巧妙地将中的噪声掩码概念引入视频生成架构,通过控制噪声掩码来实现对任意子序列的预测,无需修改模型架构。
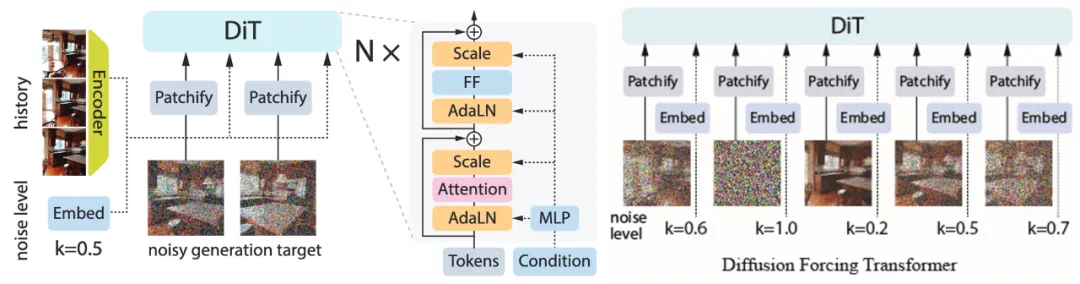
DFoT训练完成后,可以灵活地进行采样。例如,通过控制噪声掩码,可以选择使用前几帧作为条件,或进行无条件生成,或使用特定长度的历史作为条件。
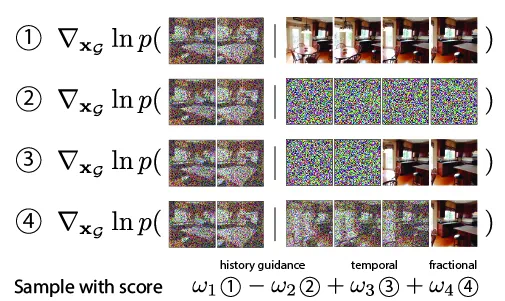
基于此,论文提出了一系列“历史引导”算法,进一步提升了模型性能。
实验结果:
DFoT在Kinetics 600数据集上超越了所有同架构的视频扩散算法,甚至与谷歌的闭源大模型结果不相上下。 在RealEstate10K数据集上,DFoT实现了单图生成近千帧的突破性成果。
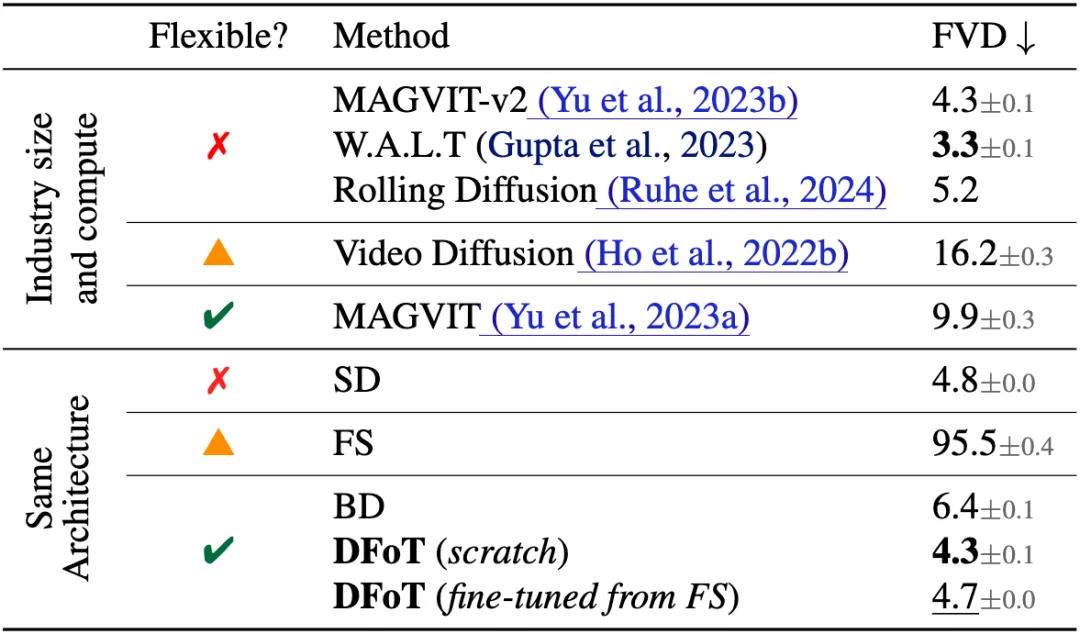


总结:
DFoT算法及其提出的“历史引导”策略显著提升了视频扩散模型的性能。该研究提供了完整的开源实现和Huggingface在线体验,方便研究者进一步探索。 Huggingface地址: