










通过分析乐队过往演出歌单,探究其现场表演的独特性。本文介绍一个基于setlist.fm api 的数据分析项目,旨在量化乐队演出歌单的多样性。该项目避免使用tableau,而是自主构建数据收集和分析工具,技术栈选择node.js。 github 项目地址:setlist-analysis
独特性评分算法
项目核心在于评估乐队演出歌单的独特性和多样性。算法包含三个关键指标:
-
歌曲独特性分数: 衡量一年内,乐队演出中歌曲重复率。分数越高,歌曲选择越多样化。
-
歌单独特性分数: 评估一年内,每场演出的歌单与其他演出的差异程度。歌单重复率越低,分数越高。
-
序列独特性分数: 分析歌曲播放顺序的独特性,识别重复出现的歌曲序列。
最终的总独特性分数综合以上三项指标,全面评估乐队现场表演的多样性。
案例分析:Phish vs. Taylor Swift
下图展示了Phish和Taylor Swift的案例对比:

-
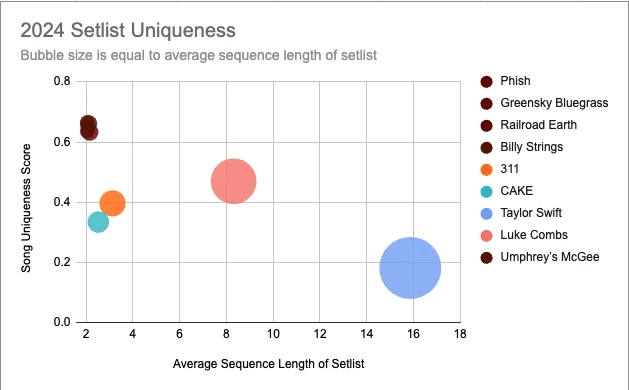
Phish: 高独特性分数,歌曲选择、歌单排列和序列变化显著,体现了其即兴表演风格。序列长度短,平均仅2.05,每场演出都独具特色。
-
Taylor Swift: 低独特性分数,歌单相对一致,可能与大型演出的制作需求有关。序列长度长,平均15.87,演出体验更稳定、可预测。
下图是歌曲独特性分数与平均序列长度的散点图,更直观地展现了不同乐队的差异:
未来规划
未来计划添加以下功能:
-
稀有度分数: 评估歌曲在乐队所有演出中出现的频率,突出罕见曲目。
-
新近度分数: 衡量乐队最近演出中新歌的比例,体现其对新旧作品的侧重。
挑战与展望
项目初期面临Spotify API变更的挑战,最终选择仅依赖SetList.fm API。未来计划扩展评分系统,创建用户友好的数据展示界面,并分析不同类型和年代乐队的演出模式。 这是一个将音乐爱好与数据分析技术结合的有趣项目,期待其未来的发展。