










Python 提供多种内置数据结构用于组织数据,包括列表、字典、元组和集合。
根据 Python 3 文档,集合是无序的、不包含重复元素的集合。其主要用途包括成员测试和去除重复项。集合还支持集合运算,如并集、交集、差集和对称差集。
本文将通过示例阐述以上定义中的每个特性,并讲解集合的创建方法。
使用 set() 函数初始化集合:
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> type(s1)
<class 'set'>使用 {} 初始化集合:
>>> s2 = {3, 4, 5}
>>> s2
{3, 4, 5}
>>> type(s2)
<class 'set'>两种方法均有效。但如果需要创建空集合呢?
>>> s = {}
>>> type(s)
<class 'dict'>使用空花括号将创建一个字典,而非集合。
为简便起见,本文示例使用整数集合,但集合可包含所有 Python 支持的可哈希[1]数据类型,例如整数、字符串和元组,但不包括列表或字典等可变类型。
>>> s = {1, 'coffee', [4, 'python']}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'了解了集合的创建方法及其可包含的元素类型后,我们来探讨一下为什么应该将集合纳入你的编程工具箱。
根据 Python Hitchhiker's Guide[3]:
当经验丰富的 Python 开发者(Pythonista)遇到不够“Pythonic”的代码时,通常认为这些代码不符合通用指南,表达意图的方式不够理想(可读性差)。
让我们看看集合如何提升代码可读性并提高程序执行效率。
>>> s = {1, 2, 3}
>>> s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing也无法使用切片修改:
>>> s[0:2] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'set' object is not subscriptable
但如果需要去除重复项或进行集合运算(如并集),则应该使用集合。
迭代时,集合的效率优于列表。原因涉及集合的内部实现细节,感兴趣的读者可以参考以下链接:
- 时间复杂度[4]
- set() 的实现[5]
- Python 集合 vs 列表[6]
- 列表中使用集合的优缺点[7]
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = [] >>> for item in my_list: ... if item not in no_duplicate_list: ... no_duplicate_list.append(item) ... >>> no_duplicate_list [1, 2, 3, 4]
或者使用列表推导式:
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = [] >>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list] [None, None, None, None] >>> no_duplicate_list [1, 2, 3, 4]
现在,我们可以使用集合:
>>> my_list = [1, 2, 3, 2, 3, 4] >>> no_duplicate_list = list(set(my_list)) >>> no_duplicate_list [1, 2, 3, 4]
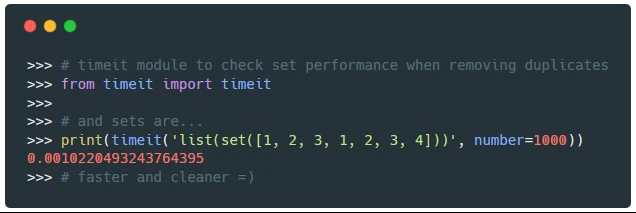
使用 timeit 模块比较列表和集合去除重复项的效率:
使用集合比列表推导式更简洁,效率更高。
注意:集合是无序的,转换为列表后元素顺序可能发生变化。
Python 之禅[8]:
优美胜于丑陋
明了胜于晦涩
简洁胜于复杂
扁平胜于嵌套
集合正是如此。
my_list = [1, 2, 3]
>>> if 2 in my_list:
... print('Yes, this is a membership test!')
...
Yes, this is a membership test!集合的成员测试效率更高:
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = list(range(1000))",
... number=1000)
12.459663048726043>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = set(range(1000))",
... number=1000)
.12354438152988223注意:以上测试来自 StackOverflow[9]。
对于大型列表,将其转换为集合可以提高成员测试效率。
add() 用于添加单个元素:
>>> s = {1, 2, 3}
>>> s.add(4)
>>> s
{1, 2, 3, 4}update() 用于添加多个元素:
>>> s = {1, 2, 3}
>>> s.update([2, 3, 4, 5, 6])
>>> s
{1, 2, 3, 4, 5, 6}集合会自动去除重复元素。
>>> s = {1, 2, 3}
>>> s.remove(3)
>>> s
{1, 2}
>>> s.remove(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 3discard() 不会引发异常:
>>> s = {1, 2, 3}
>>> s.discard(3)
>>> s
{1, 2}
>>> s.discard(3)
>>> # 无任何操作pop() 用于随机移除一个元素:
>>> s = {1, 2, 3, 4, 5}
>>> s.pop() # 移除一个任意元素
1
>>> s
{2, 3, 4, 5}clear() 用于清空集合:
>>> s = {1, 2, 3, 4, 5}
>>> s.clear() # 清空集合
>>> s
set()>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>> s1.union(s2) # 或 's1 | s2'
{1, 2, 3, 4, 5}>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s3 = {3, 4, 5}
>>> s1.intersection(s2, s3) # 或 's1 & s2 & s3'
{3}>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.difference(s2) # 或 's1 - s2'
{1}>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.symmetric_difference(s2) # 或 's1 ^ s2'
{1, 4}如有任何疑问,请随时提出。此外,Python 速查表[10]中也包含了集合的相关内容[11],方便查阅。