










阿里云通义千问团队在最新论文中揭示了混合专家模型(moe)训练中的一个关键问题,并提出了一种创新的解决方案。该问题在于现有moe训练框架普遍采用局部负载均衡损失(lbl),导致专家激活不均衡,限制了模型性能和专家特异性。

该团队提出的方法通过轻量级通信机制,将局部负载均衡提升为全局负载均衡。这使得模型能够更好地利用数据多样性,从而提高专家特异化程度和整体模型性能。
 - 论文:《Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models》
- 论文:《Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models》
- 论文链接:https://www.php.cn/link/b294fccdfe95bc7f7dd813216a821a76
MoE训练中的挑战与解决方案
MoE通过路由机制动态激活模型参数,提升了模型容量。然而,基于TopK的稀疏激活容易导致专家激活不均衡,少数专家被过度利用,其余专家资源浪费。为此,通常引入LBL来平衡专家激活。
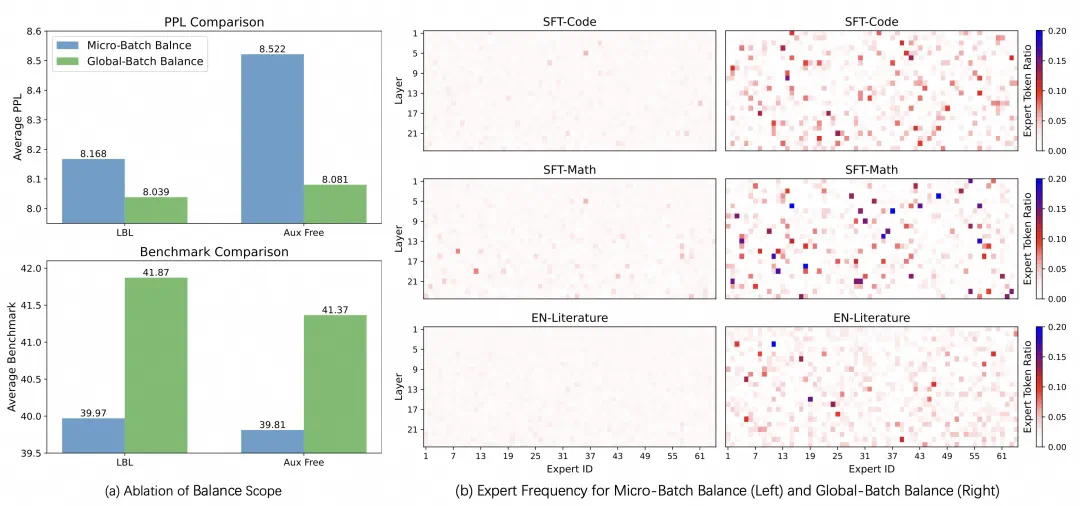
现有框架的LBL通常在局部(mini-batch)层面计算,这在mini-batch数据缺乏多样性时会限制专家特异化。 阿里云团队的方案通过跨mini-batch同步专家激活频率,实现全局LBL计算,有效解决了这个问题。
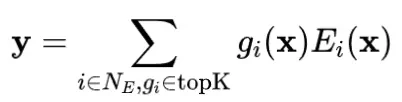
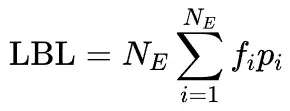
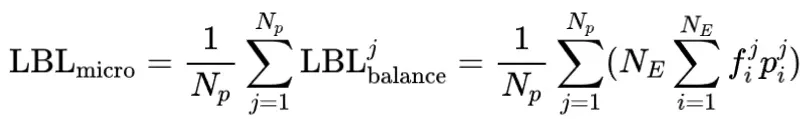
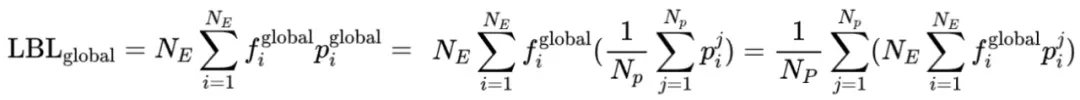
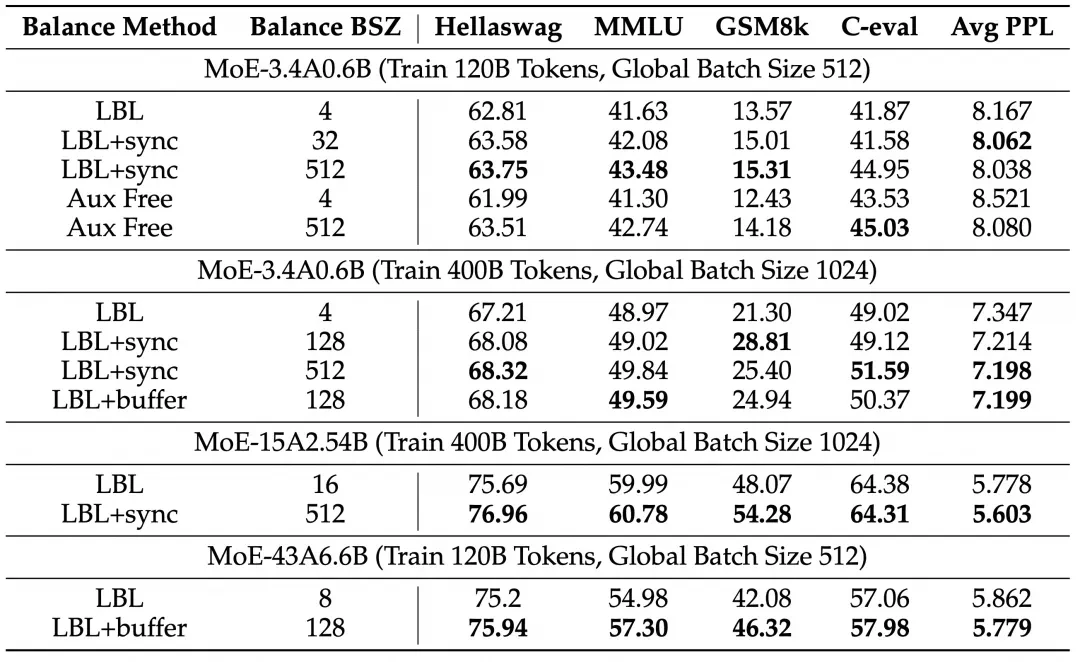
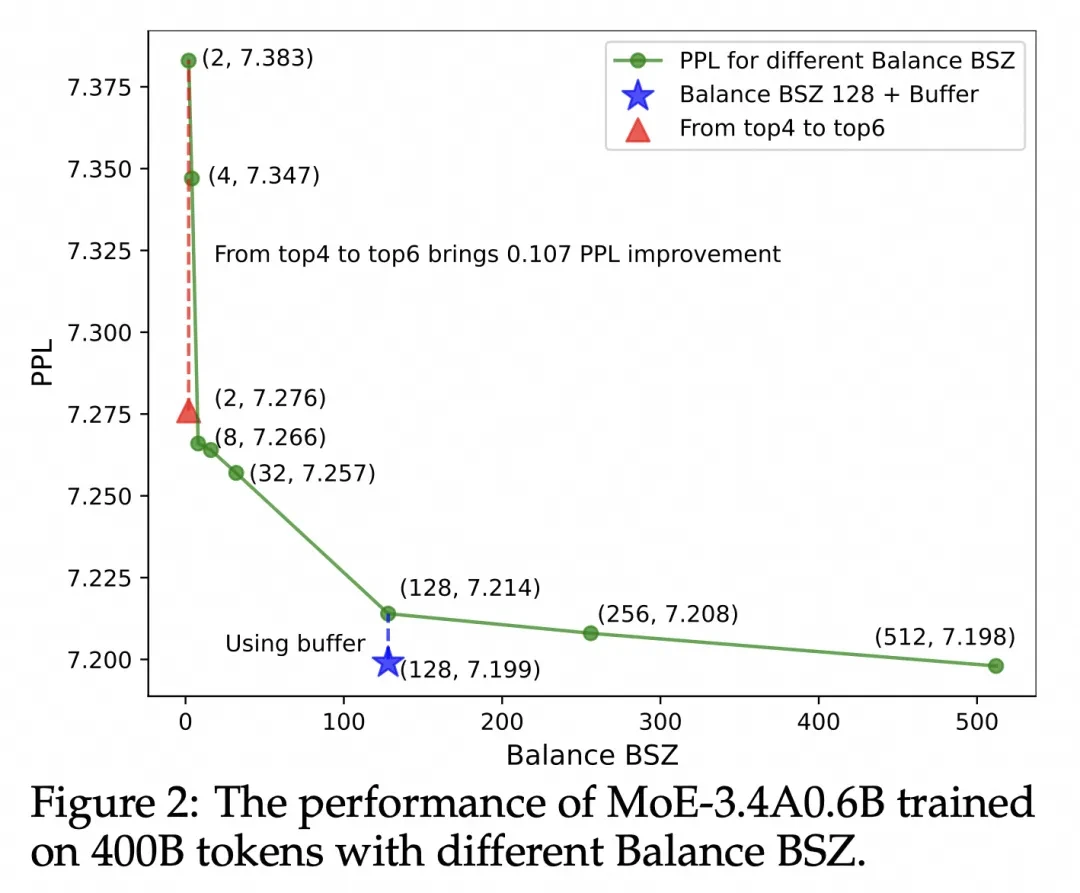
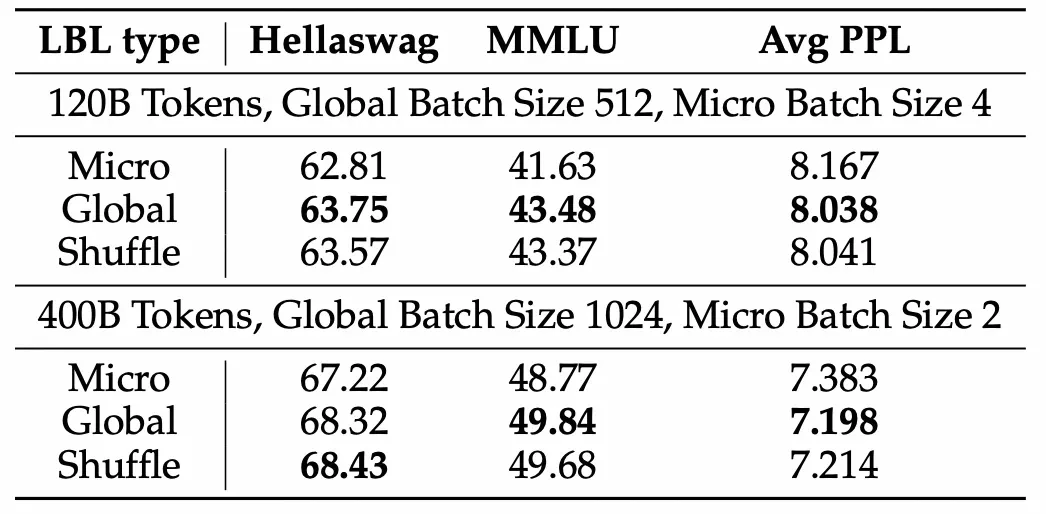
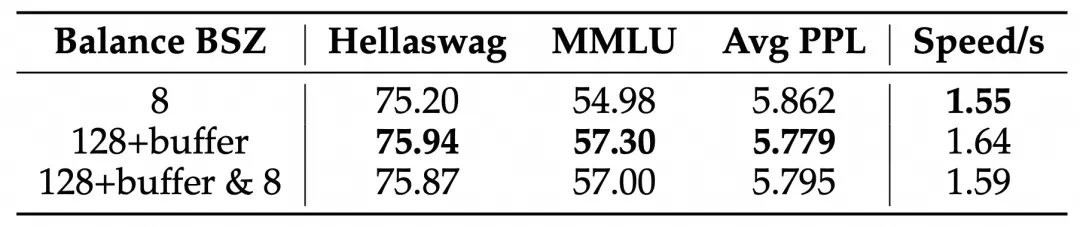
实验结果表明,该方法显著提升了模型性能和专家特异性,尤其是在大规模模型训练中效果明显。 此外,研究还发现,添加少量局部LBL可以进一步提高训练效率,而不会显著影响模型性能。
这项研究为MoE模型的训练提供了新的思路,有助于构建更高效、更可解释的大规模模型。 虽然实验主要集中在语言模型领域,但其方法具有广泛的应用前景。