










字节跳动研究团队的视频理解大模型tarsier迎来了重大升级,推出了第二代模型tarsier2及其技术报告。此前发布的tarsier-7b/34b已成为最强大的开源视频描述模型,仅次于闭源模型gemini-1.5-pro和gpt-4o。那么,tarsier2又有哪些突破呢?
让我们先看看Tarsier2对经典影视片段的理解:

 《燕子,没有你我怎么活》
《燕子,没有你我怎么活》
《曹操盖饭》
Tarsier2不仅精准捕捉人物动作(例如小岳岳追车、下跪,曹操的挥舞动作),还巧妙结合字幕信息,深入分析人物动机、心理,理解人物关系和剧情发展。
Tarsier2 视频描述效果合集
Tarsier2在视频描述任务上的表现同样出色,无论是真人还是动画、横屏还是竖屏、多场景还是多镜头,都能精准捕捉核心视觉元素和动态事件,并用简洁的语言进行描述,且很少出现幻觉。其性能已可与GPT-4o媲美。

Tarsier2的“火眼金睛”是如何炼成的?
Tarsier2是一个7B参数的轻量级模型,支持动态分辨率,能够理解长达数十分钟的视频,尤其擅长分析几十秒的短视频片段。其强大的视频理解能力源于精细的预训练和后训练阶段:
预训练阶段:
Tarsier2在4000万个互联网视频-文本数据上进行预训练。团队通过海量收集互联网视频-文本数据,并设计了一套严谨的数据筛选流程(分镜、过滤、合并),确保训练数据的质量。特别值得一提的是,Tarsier2筛选了大量的影视剧解说视频,帮助模型理解更深层次的情节信息。
后训练阶段:
后训练分为SFT和DPO两个阶段:
- SFT (监督微调): 在人工标注的视频描述数据上进行训练,并引入针对每个子事件的具体定位信息,强化模型对时序信息和视觉特征的关注。
 SFT数据样例
SFT数据样例
- DPO (数据增强): 在自动化构造的正负样本上进行DPO训练,正样本来自模型对原始视频的预测,负样本来自模型对经过随机扰动的视频的预测。这种方法提高了描述的准确性和完整性,减少了幻觉。
性能测试:
Tarsier2在19个视频理解公开基准上进行了测试,与10多个最先进的开源模型(Qwen2-VL、InternVL2.5、LLaVA-Video等)和闭源模型(Gemini-1.5, GPT-4o)进行了比较。结果显示,Tarsier2在视频描述、短/长视频问答等通用视频理解任务上表现出色。
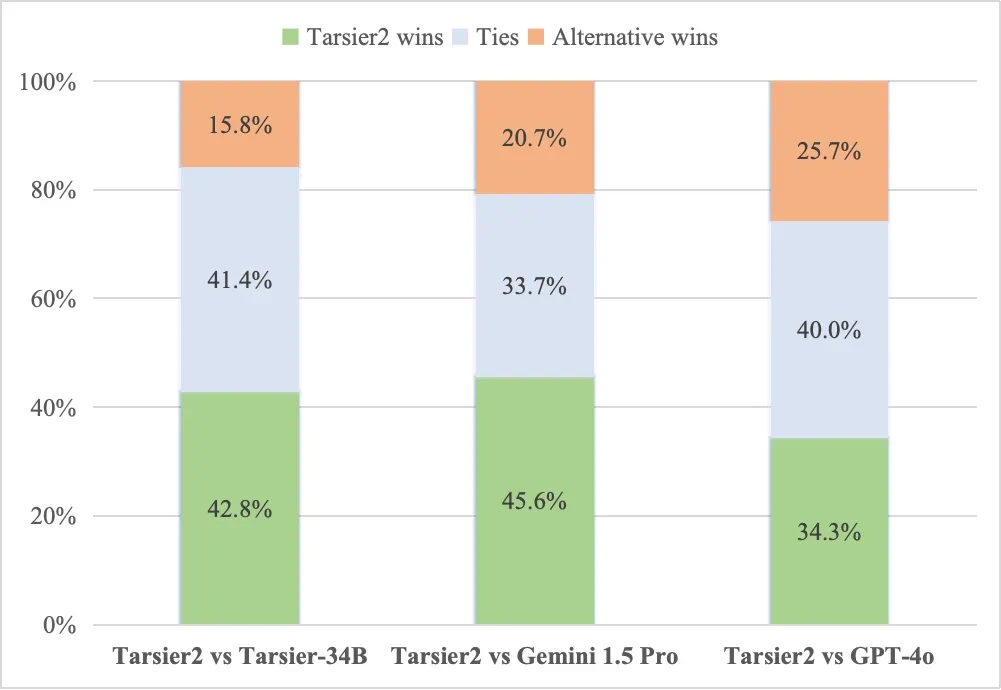 视频描述质量人工评估结果
视频描述质量人工评估结果
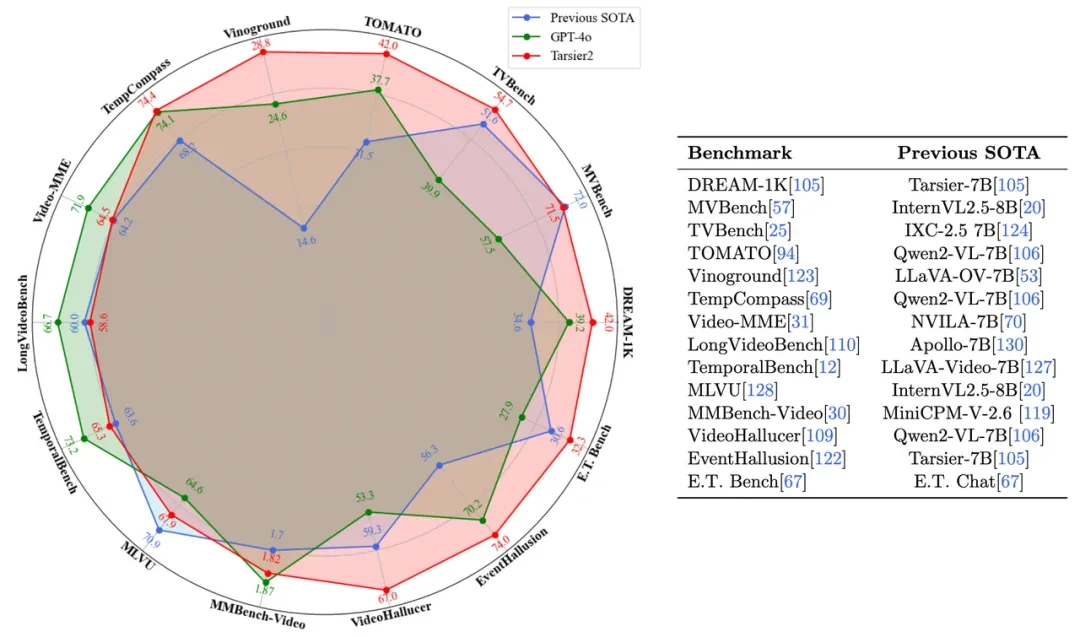 Tarsier2在广泛的视频理解任务上树立了新的标杆
Tarsier2在广泛的视频理解任务上树立了新的标杆
Tarsier2还在机器人和智能驾驶等下游任务中展现了强大的泛化能力。
机器人场景
智能驾驶场景
未来展望:
Tarsier2在生成准确详细的视频描述方面超越了现有模型,并在广泛的视频理解任务中树立了新的标杆。 它在多模态融合领域迈出了坚实的一步,未来有望在人工智能发展中发挥更大的作用。

论文地址:https://www.php.cn/link/e3c87529e817b9f8468c02ee8c81ed89 项目仓库:https://www.php.cn/link/b8d889c4e9b34bc7dc7a93a2a9a91070 HuggingFace:https://www.php.cn/link/bdee0997d3fb6be8515a432051fe4e5c