










腾讯混元团队揭示大模型浮点量化训练规律,找到最佳性价比配置

大模型低精度训练和推理是降低成本的关键方向,而浮点量化因其损耗小而备受关注。然而,现有整数量化经验能否直接应用于浮点量化?浮点量化是否存在极限?这些问题亟待解答。腾讯混元团队近期发表的论文《Scaling Laws for Floating–Point Quantization Training》(https://www.php.cn/link/40216b76ee25df53804927a16af4bc8c Laws。
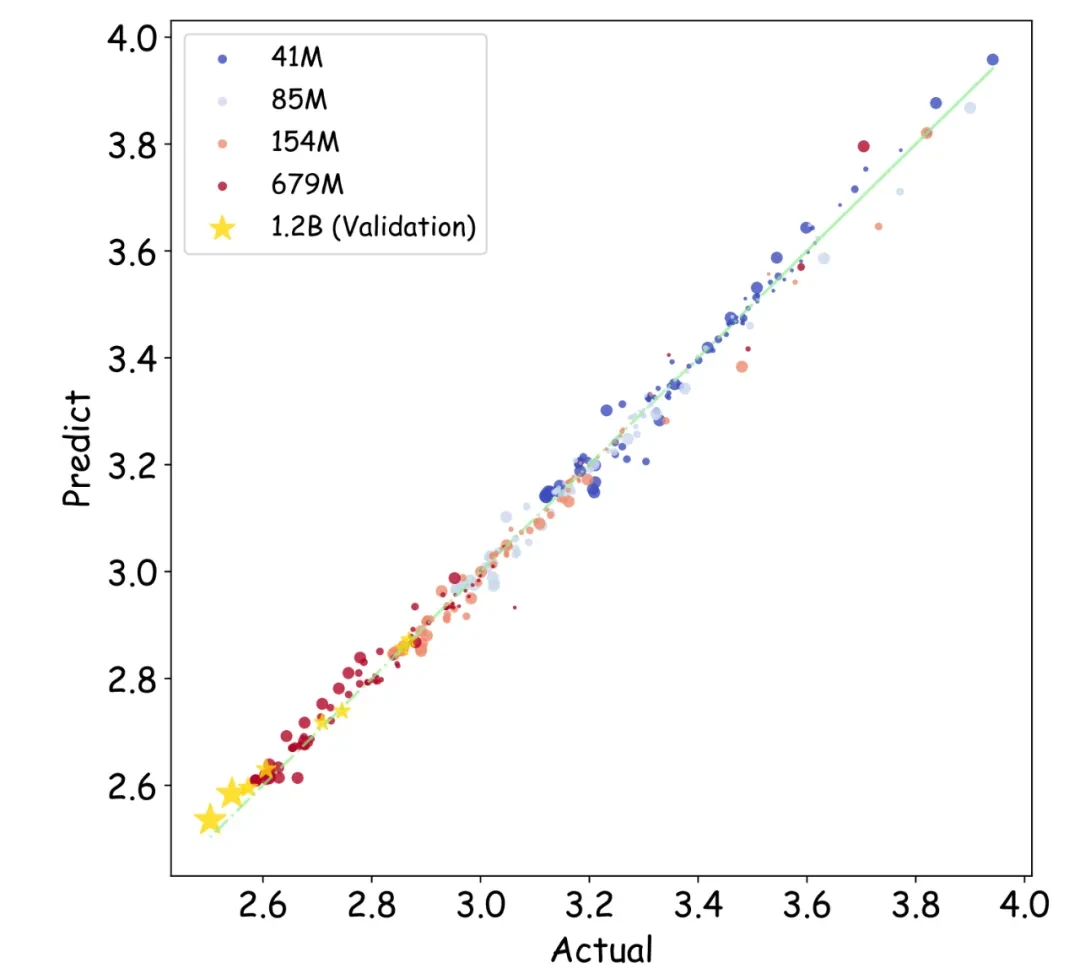
该研究通过366组不同参数规模和精度的浮点量化训练实验,综合考虑模型大小(N)、训练数据量(D)、指数位(E)、尾数位(M)以及量化放缩因子共享粒度(B),最终得出统一的Scaling Law公式:
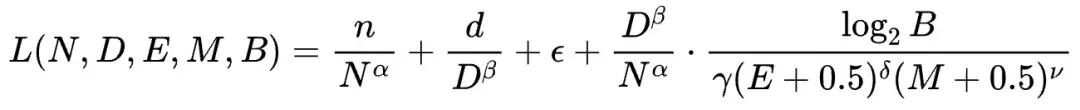
基于此公式,研究团队得出以下重要结论:
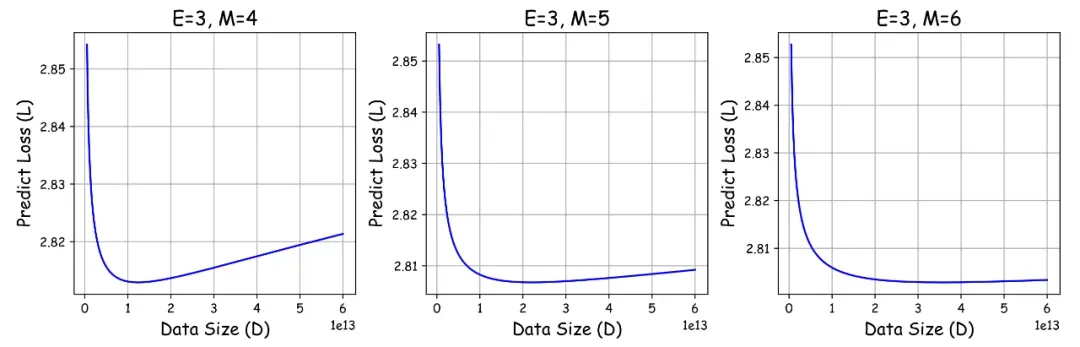
- 存在模型效果极限及最佳数据量: 无论精度如何,每个模型都存在一个最佳数据量,超过此量反而会降低效果。
- 最佳性价比精度范围: 在大范围算力下,理论预测的最佳性价比精度位于4-8比特之间。
- 资源受限下的最优配置策略: 该Scaling Laws可指导在不同计算资源下,确定最佳性价比的浮点量化训练精度、模型参数量和训练数据量。
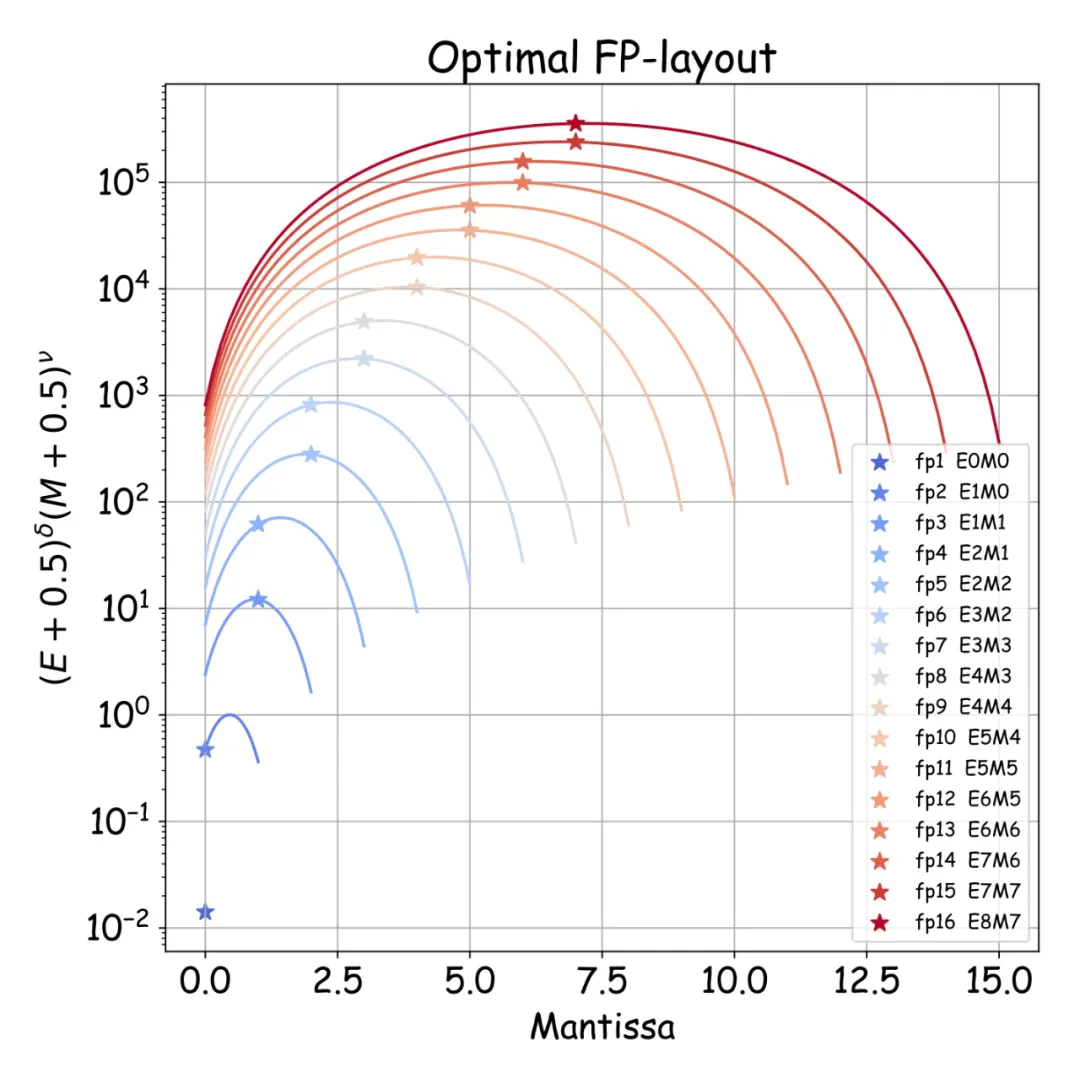
浮点数最佳配比及精细量化
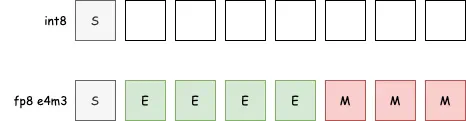
研究团队还深入分析了指数位(E)和尾数位(M)对模型效果的影响,得出其最佳配比规律:
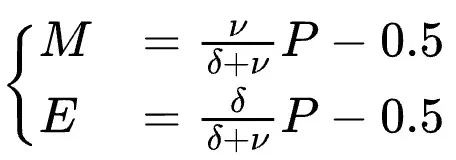
并定量研究了放缩因子共享粒度(B)的影响,发现验证损失与B的对数成正比:
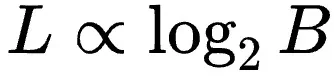
效果屏障与资源受限下的最优解
该研究发现,由于效果屏障的存在,即使资源无限,训练数据量也不应超过Dcrit:
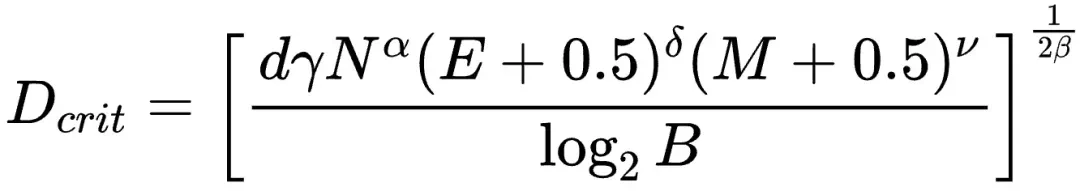
在资源受限的情况下,通过求解方程组,可以得到最佳性价比精度和参数量N与数据量D的配置策略,以及精度P与参数量N之间的“汇率”关系:
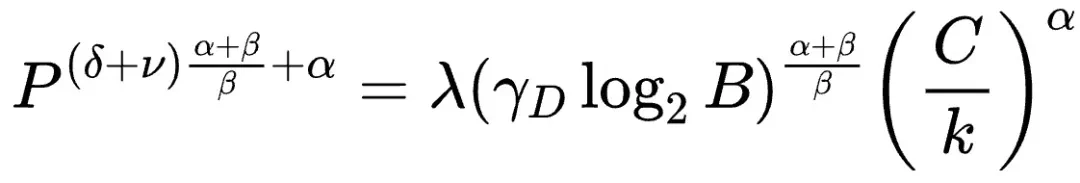
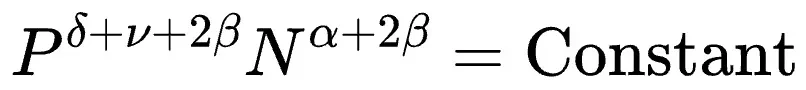
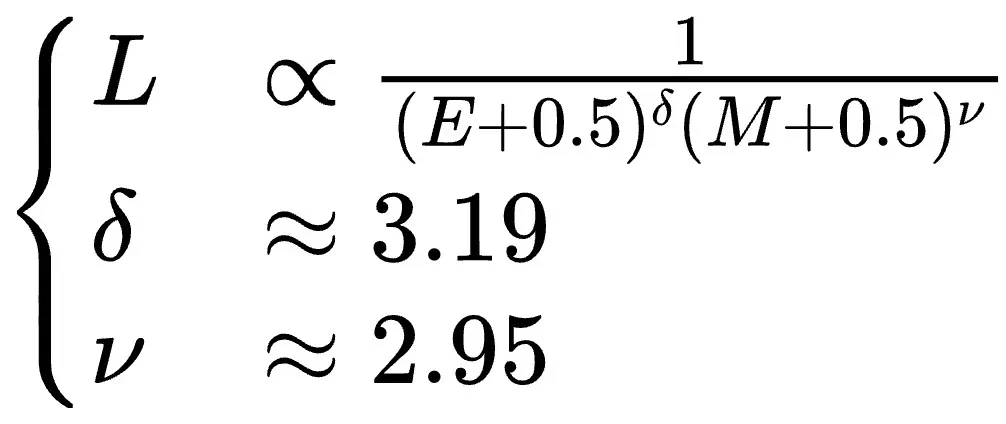
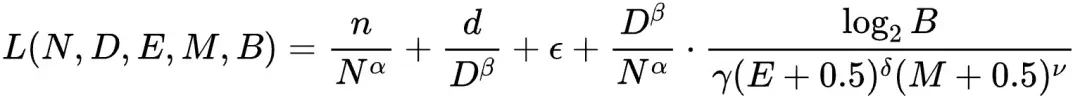
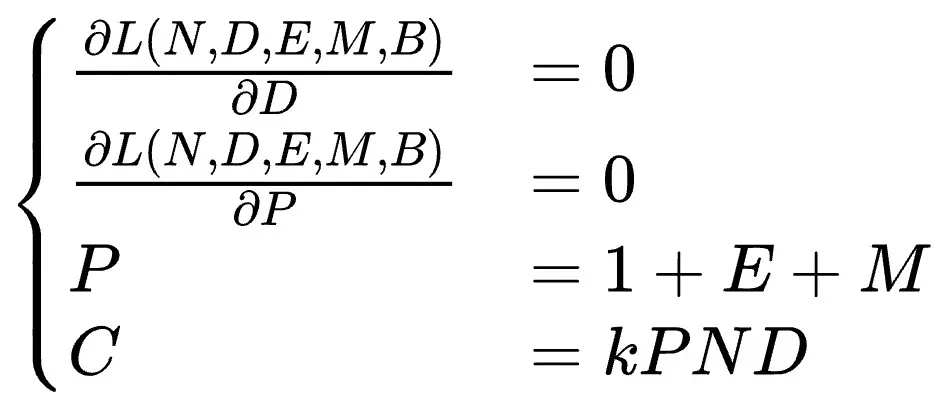
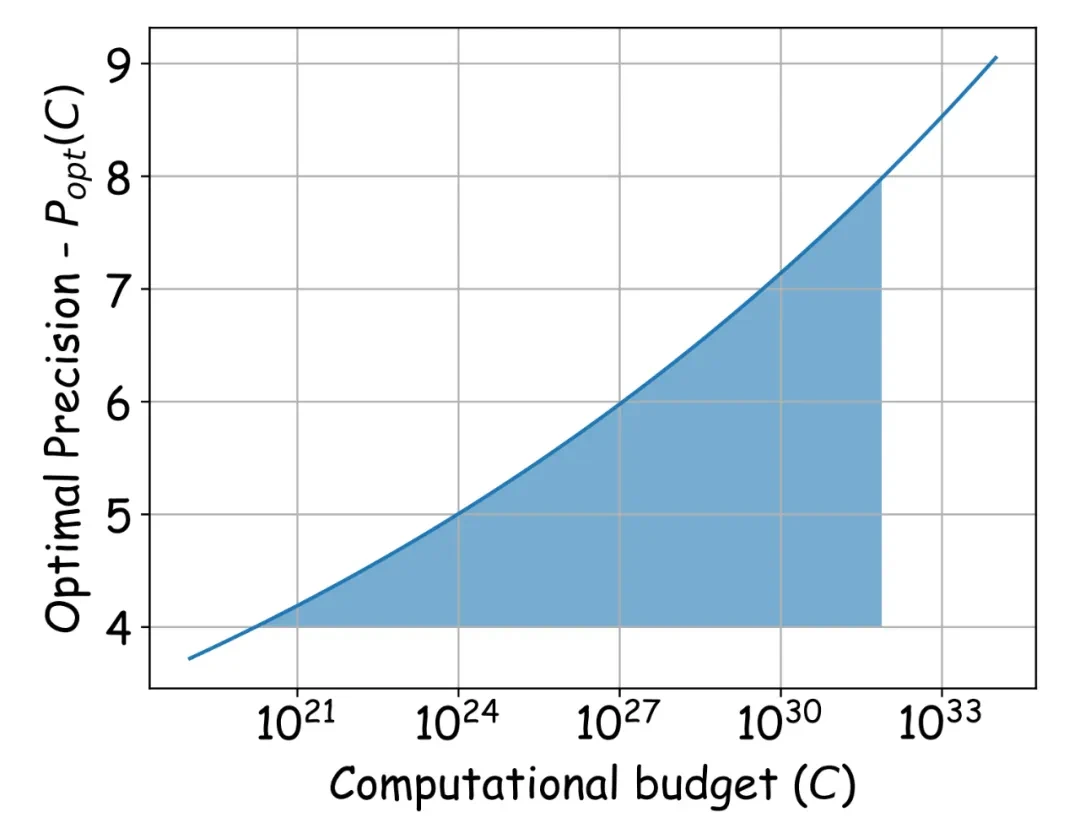
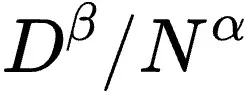
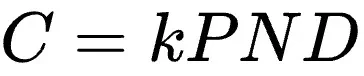
这项研究为大模型浮点量化训练提供了重要的理论指导,对降低训练成本和推动大模型应用具有重要意义。 它不仅为优化训练配置提供了依据,也为硬件厂商优化浮点运算能力和研究人员开展相关创新提供了新的方向。